orgtre
orgtre OP t1_iqx4i2s wrote
Reply to comment by draypresct in The returns to learning the most common words, by language [OC] by orgtre
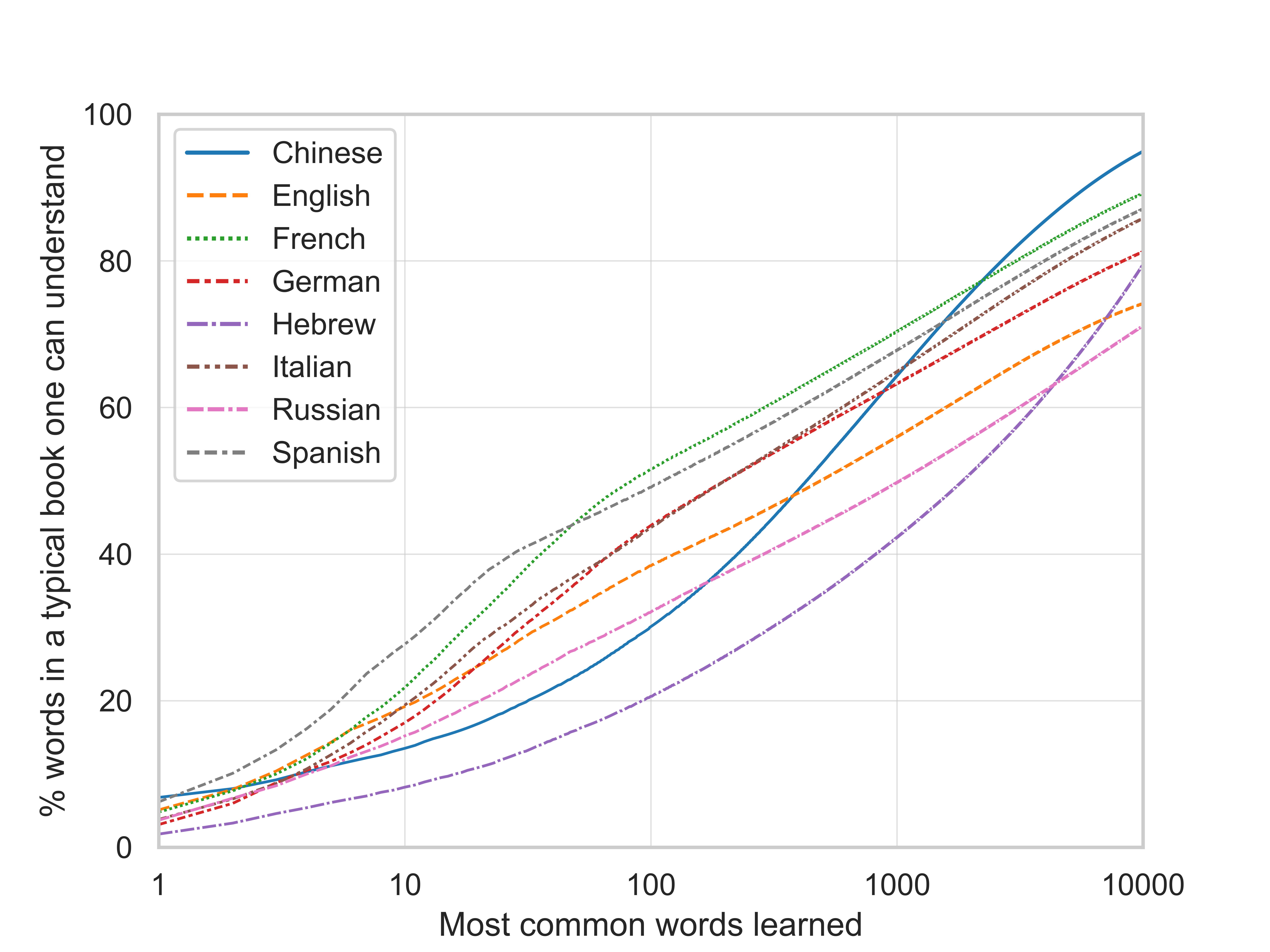
Yes, the data comes from the same books. For each language I create an ordered list of the most frequent words, looking like this. The graph then just plots the rank of the word on the x-axis and the cumulative relative frequency (column "cumshare" in the csv files) on the y-axis.
The answer to your last question is hence also yes. It brings up the question of how representative the underlying corpus is. I wrote a bit about that here and there is also this paper. To be very precise the y-axis title should be "% words in a typical book from the Google Books Ngram corpus one can understand"; to the extent that one thinks the corpus is representative of a typical book one might read, the "from the Google Books Ngram corpus" part can be omitted.
orgtre OP t1_iqwzdvz wrote
Reply to comment by e3928a3bc in The returns to learning the most common words, by language [OC] by orgtre
Exactly. To clarify: The original comment has 15 "words" (Google counts "," as a separate word...), 2 of which are "I", and 2/15 is around 13%.
The most common Chinese word is "的", which Google translates as "of", and at least in Google's selection of books it makes up 7% of all words.
orgtre OP t1_iqwdfqy wrote
Reply to comment by nic333rice in The returns to learning the most common words, by language [OC] by orgtre
Also, if someone with knowledge of Chinese would glance through the source repo for any obvious problems, that would be very helpful!
orgtre OP t1_iqwcedp wrote
Reply to comment by nic333rice in The returns to learning the most common words, by language [OC] by orgtre
Yes, it is strange. The analysis takes words into account – here is the underlying wordlist. The words were created by Google and the process is described on page 12 of the revised online supplement of this paper as follows: > The tokenization process for Chinese was different. For Chinese, an internal CJK (Chinese/Japanese/Korean) segmenter was used to break characters into word units. The CJK segmenter inserts spaces along common semantic boundaries. Hence, 1-grams that appear in the Chinese simplified corpora will sometimes contain strings with 1 or more Chinese characters.
I think the problem is that the Chinese corpus is much smaller than the other corpora. A better way to create this graph might have been to only include words that occur at least once every say one million words, but this would have needed quite some code changes and I'm not sure it is better. Right now the count of the total number of words per language, the denominator in the y-axis, includes all "words".
Moreover, the Chinese corpus might be based on a more narrow selection of books than the other corpora, as a look at the list of most common 5-grams (sequences of 5 "words") reveals.
orgtre OP t1_iqw7nyb wrote
Reply to comment by Zoomaya in The returns to learning the most common words, by language [OC] by orgtre
Probably yes then... all the lines are in quite distinct colors.
orgtre OP t1_iqvwyu3 wrote
Reply to comment by trucorsair in The returns to learning the most common words, by language [OC] by orgtre
Sorry, not by me though. I kind of like the title as it's short while still being reasonably descriptive, but can change it if many people agree with you.
orgtre OP t1_iqvsjli wrote
Reply to comment by trucorsair in The returns to learning the most common words, by language [OC] by orgtre
Maybe an example makes it more clear: After learning the 1000 most frequent French words, one can understand more than 70% of all words, counted with duplicates, occurring in a typical book in the French Google Books Ngram Corpus.
 The returns to learning the most common words, by language [OC]
The returns to learning the most common words, by language [OC]Submitted by orgtre t3_xujlqk in dataisbeautiful
orgtre OP t1_iqxdr8t wrote
Reply to comment by RedditSuggestion1234 in The returns to learning the most common words, by language [OC] by orgtre
Yes, basically. But in addition to differences in vocabulary diversity, differences between the lines of different languages might be due to differences in the collections of books (corpora) these lines are based on.
On thing that seems to play a role is that the corpora are of different sizes: Lines for both Hebrew and Chinese look quite different from the other languages, and these corpora are also much smaller than the others. Hebrew and Chinese both also use a non-Roman alphabet, but so does Russian, whose corpus is larger. So this is some indication of that Hebrew and Chinese stand apart because of their smaller corpus size.