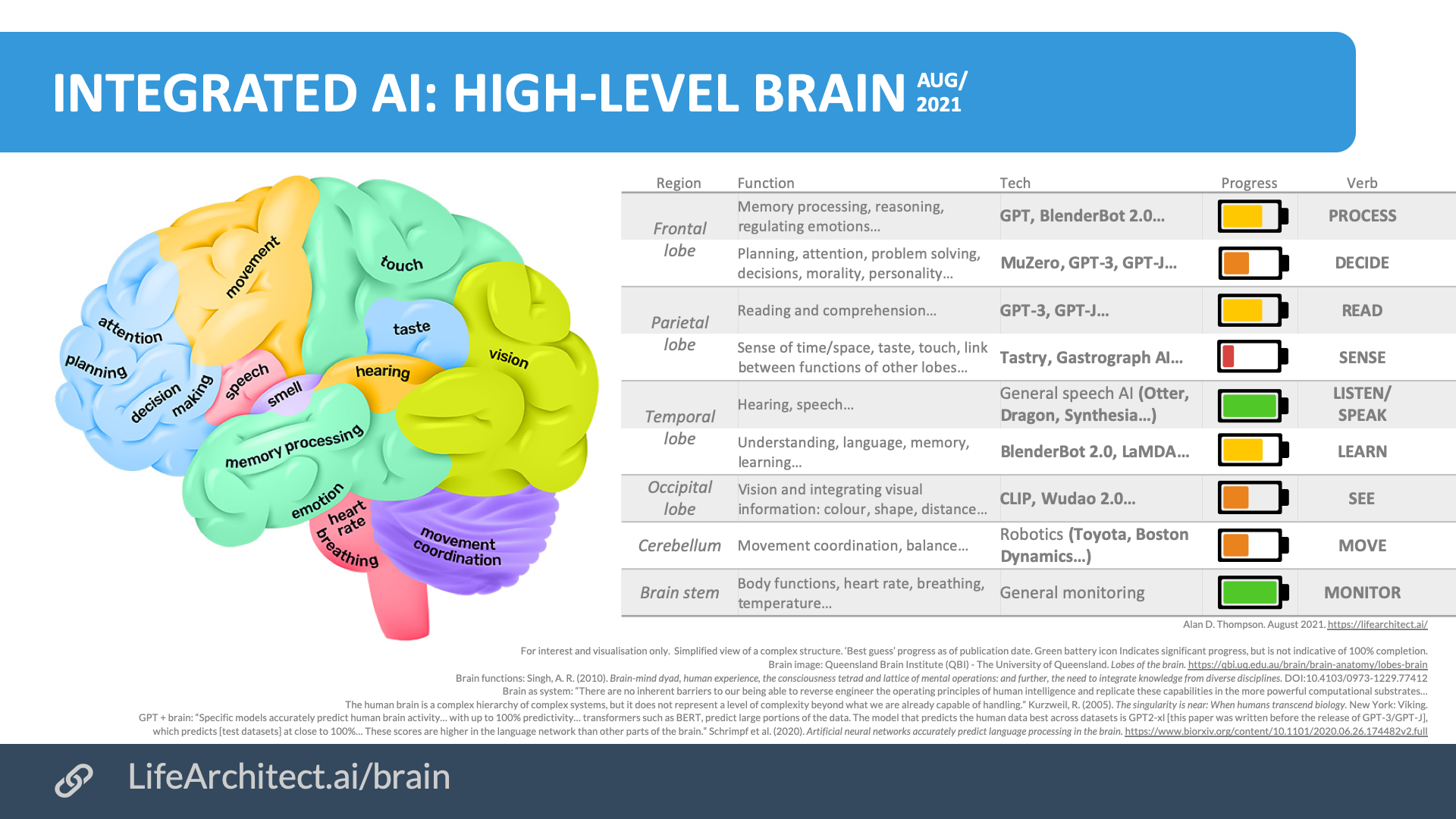
 What do you guys think of this concept- Integrated AI: High Level Brain?
What do you guys think of this concept- Integrated AI: High Level Brain?Submitted by Akimbo333 t3_10easqx in singularity
CypherLH t1_j4t6bbs wrote
Reply to comment by iiioiia in What do you guys think of this concept- Integrated AI: High Level Brain? by Akimbo333
Its fair to assume the people inside OpenAI and Microsoft have access to versions of chatGPT without the shackles and with way more than 8k tokens of working memory. Of course I am just speculating here, but this seems like a safe assumption.
To say nothing of companies like google that seems to be building the same sorts of models and just not publicly releasing them.
iiioiia t1_j4t7uyu wrote
I bet it's even worse: I would bet my money that only a very slim minority of the very most senior people will know that certain models are different than others, and who has access to those models.
For example: just as the CIA/NSA/whoever have pipes into all data centres and social media companies in the US, I expect the same thing at least will happen with AI models. Think about the propaganda this is going to enable, and think how easily it will be for them to locate people like you and I who talk about such things.
I dunno about you, but I feel like we are approaching a singularity or bifurcation point of sorts when it comes to governance....I don't think our masters are going to be able to resist abusing this power, and it seems to me that they've already pushed the system dangerously close to its breaking point. January 6 may look like a picnic compared to what could easily happen in the next decade, we seem to be basically tempting fate at this point.
CypherLH t1_j4ujwb1 wrote
Probably not too far off. The consumer grade AI that you and I will have access to will be cool and keep getting more powerful...but the full unshackled and unthrottled models that are only available in the upper echelons will probably be orders of magnitude more powerful and robust. And they'll use the consumer grade AI as fodder for training the next generation AI's as well, so we'll be paying for access to consumer grade AI but we'll also BE "the product" in the sense that all of our interactions with consumer grade AI will go into future AI training and of course data profiling and whatnot. This is presumably already happening with GPT-3 and chatGPT and the various image generation models, etc. This is kind of just an extension of what has been happening already, with larger corporations and organizations leveraging their data collection and compute to gain advantage....AI is just another step down that path and probably a much larger leap in advantage.
And I don't see anyway to avoid this unless we get opensource models that are competitive with MS, Google, etc. This seems unlikely since the mega corporations will always have access to vastly larger amounts of compute. Maybe the compute requirements will decline relative to hardware costs once we get fully optimized training algorithms and inference software. Maybe GPT-4 equivalent models will be running on single consumer GPU's by 2030 (of course the corps and governments will by then have access to GPT-6 or whatever....unless we hit diminishing returns on these models.
iiioiia t1_j4vtc49 wrote
> And they'll use the consumer grade AI as fodder for training the next generation AI's as well, so we'll be paying for access to consumer grade AI but we'll also BE "the product" in the sense that all of our interactions with consumer grade AI will go into future AI training and of course data profiling and whatnot.
Ya, this is a good point....I don't understand the technology enough to have a feel for how true this may be, but my intuition is very strong that this is exactly what will be the case....so in a sense, not only will some people have access to more powerful, uncensored models, those models will also have an extra, compounding advantage in training. And on top of it, I would expect that the various three latter agencies in the government will have ~full access to the entirety of OpenAI and others' work, but will also be secretly working on extensions to that work. And what's OpenAI going to do, say no?
> And I don't see anyway to avoid this unless we get opensource models that are competitive with MS, Google, etc.
Oh, I fully expect we will luckily have access to open source models, and that they will be ~excellent, and potentially uncensored (though, one may have to run their compute on their own machine - expensive, but at least it's possible). But, my intuition is that the "usable" power of a model is many multiples of its "on paper" superiority.
All that being said: the people have (at least) one very powerful tool in their kit that the government/corporations do not: the ability to transcend the virtual reality[1] that our own minds have been trained on. What most people don't know is that the mind itself is a neural network of sorts, and that it is (almost constantly) trained starting at the moment one exits the womb, until the moment you die. This is very hard to see[2] , but once it is seen, one notices that everything is affected by it.
I believe that this is the way out, and that it can be implemented...and if done adequately correctly, in a way that literally cannot fail.
May we live in interesting times lol
[1] This "virtual reality" phenomenon has been known of for centuries, but can easily be hidden from the mind with memes.
See:
https://www.vedanet.com/the-meaning-of-maya-the-illusion-of-the-world/
https://en.wikipedia.org/wiki/Allegory_of_the_cave
[2] By default, the very opposite seems to be true - and, there are hundreds of memes floating around out there that keep people locked into the virtual reality dome that has been slowly built around them throughout their lifetime, and at an accelerated rate in the last 10-20 years with the increase in technical power and corruption[3] in our institutions.
[3] "Corruption" is very tricky: one should be very careful presuming that what may appear to be a conspiracy is not actually just/mostly simple emergence.
Viewing a single comment thread. View all comments