 What do you guys think of this concept- Integrated AI: High Level Brain?
What do you guys think of this concept- Integrated AI: High Level Brain?Submitted by Akimbo333 t3_10easqx in singularity
green_meklar t1_j4reybs wrote
You don't get strong AI by plugging together lots of narrow AIs.
JavaMochaNeuroCam t1_j4tdxq0 wrote
All they need to do is encode the domain info, and then a central model integrates all those encodings. Just like we do.
Akimbo333 OP t1_j4ud77c wrote
Interesting
green_meklar t1_j5chupa wrote
I'm skeptical that what we do is so conveniently reducible.
JavaMochaNeuroCam t1_j5cmn9t wrote
Read Stanislas Dehaene "Consciousness and the Brain". Also, Erik R Kandel, Nobel Laureate, "The Disordered Mind" and "In Search of Memory".
Those are just good summaries. The evidence of disparate regions serving specific functions is indisputable. I didn't believe it either for most of my life.
For example, Wernicke's area comprehends speech. Broca's area generates speech. Neither are necessary for thought or consciousness.
Wernicke's area 'encodes' into a neural state vector the meaning of the word sounds. These meaning-bound tokens are then interpreted by the neocortex, I believe.
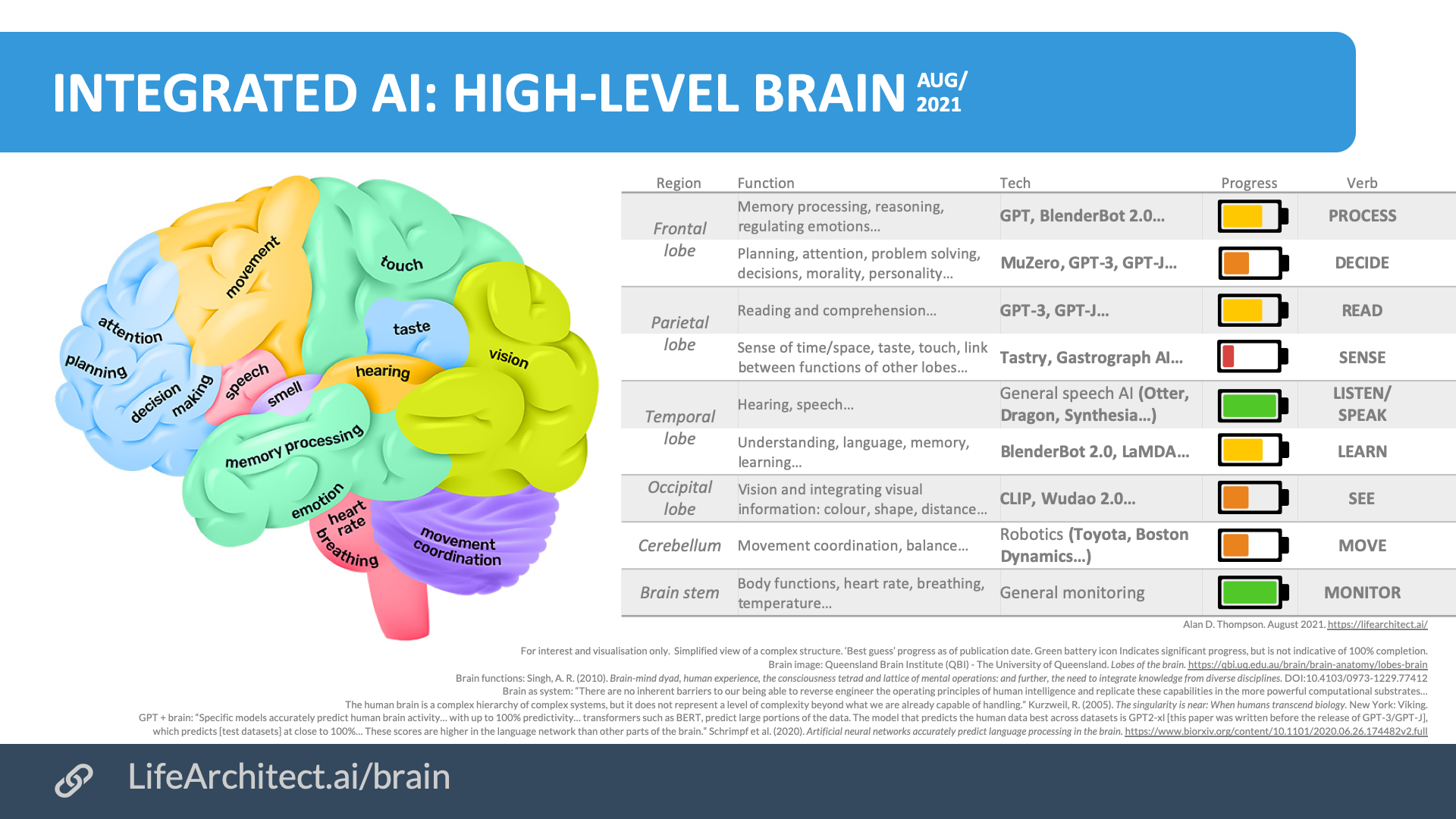
But, this graphic isn't meant to suggest we should connect them together. I think he points out that the training done for each model could be employed on a common model, and it would learn to fuse the information from the disparate domains.
green_meklar t1_j5s4i0n wrote
>The evidence of disparate regions serving specific functions is indisputable.
Oh, of course they exist, the human brain definitely has components for handling specific sensory inputs and motor skills. I'm just saying that you don't get intelligence by only plugging those things together.
>I think he points out that the training done for each model could be employed on a common model
How would that work? I was under the impression that converting a trained NN into a different format was something we hadn't really figured out how to do yet.
JavaMochaNeuroCam t1_j64e3yg wrote
Alan was really psyched about GATO (600+ tasks/domains)
I think it's relatively straightforward to bind experts to a general cognitive model.
Basically, the MOE, Mixture of Experts, would dual train the domain-specific model with simultaneous training of the cortex (language) model. That is, a pre-trained image-recognition model can describe an image (ie, a cat) in text to an LLM, but also bind it to a vector that represents the neural state that captures that representation.
So, you're just binding the language to the domain-specific representations.
Somehow, the hippocampus, thalamus and claustrum are involved in that in humans. If I'm not mistaken.
Viewing a single comment thread. View all comments