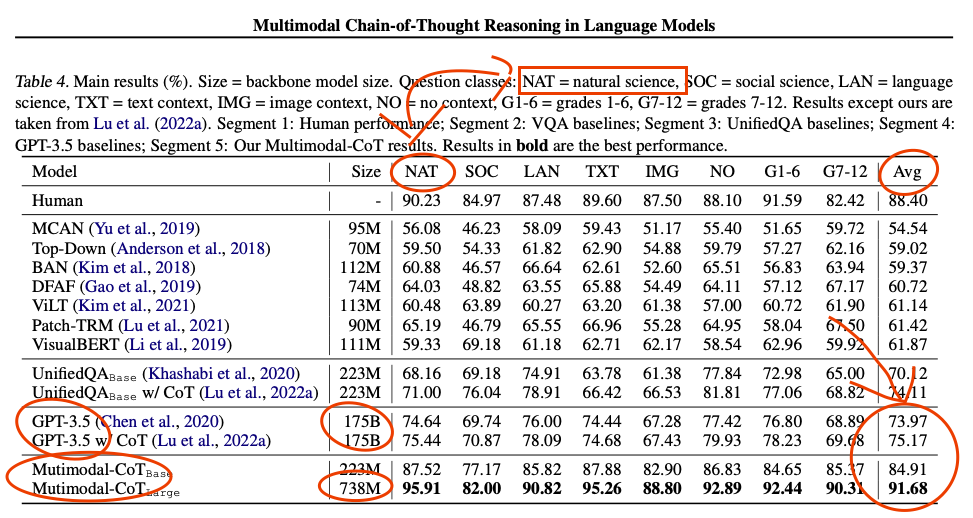
 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]EndTimer t1_j9l4tc6 wrote
Reply to comment by FirstOrderCat in What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions] by Destiny_Knight
I don't know. It's going to be in the methodology of the paper, which neither of us have read.
FirstOrderCat t1_j9l8xn9 wrote
Yes, and then reproduce results from both papers, check the code to see nothing creative happens in datasets or during training, and there are much more claims in the academia than one has time to verify.
Viewing a single comment thread. View all comments