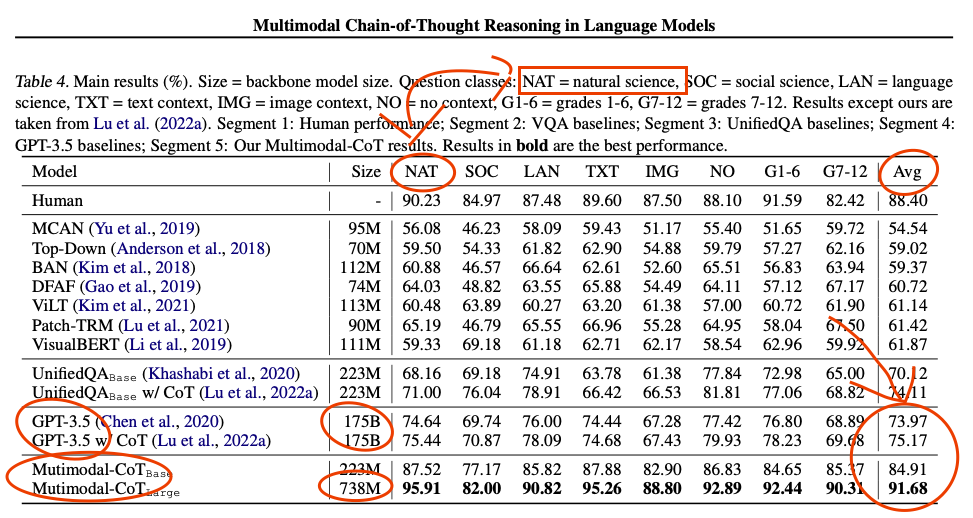
 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]EndTimer t1_j9l1xxj wrote
Reply to comment by FirstOrderCat in What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions] by Destiny_Knight
Presumably, TXT (text context). LAN (language sciences) are unlikely to have many images in their multiple choice questions. The other science domains and G1-12 probably have majority text questions.
FirstOrderCat t1_j9l4bho wrote
What is IMG for GPT then there?
How come GPT performed better without seeing context compared to seeing text context?..
EndTimer t1_j9l4tc6 wrote
I don't know. It's going to be in the methodology of the paper, which neither of us have read.
FirstOrderCat t1_j9l8xn9 wrote
Yes, and then reproduce results from both papers, check the code to see nothing creative happens in datasets or during training, and there are much more claims in the academia than one has time to verify.
iamascii t1_j9o2v76 wrote
They used the captions instead of the images. The captions are pretty descriptive imho.
FirstOrderCat t1_j9p55p9 wrote
It still doesn't answer second question.
Viewing a single comment thread. View all comments