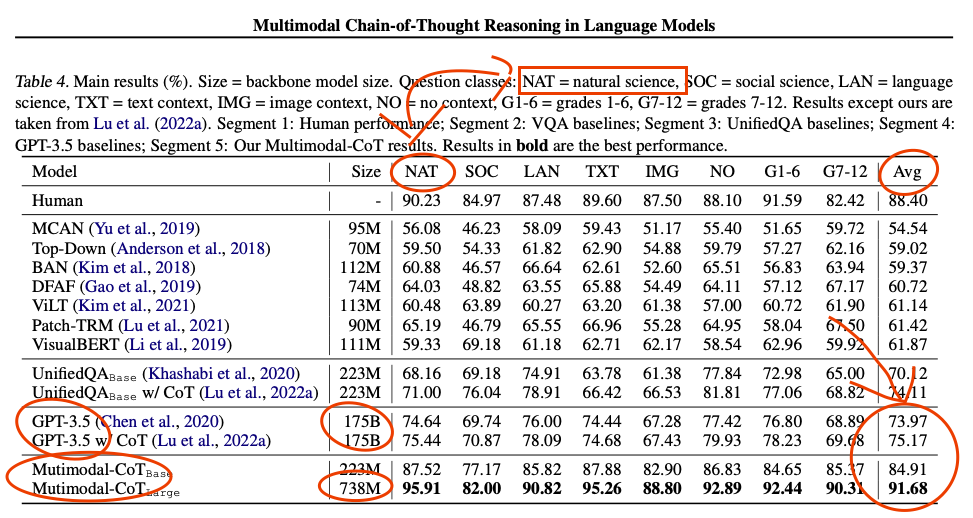
 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]dwarfarchist9001 t1_j9knt85 wrote
Reply to comment by gelukuMLG in What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions] by Destiny_Knight
It was shown recently that for LLMs ~0.01% of parameters explain >95% of performance.
gelukuMLG t1_j9kxnj4 wrote
But higher parameters allow for broader knowledge right? You can't have a 6-20B model have broad knowledge as a 100B+ model, right?
Ambiwlans t1_j9lab3g wrote
At this point we don't really know what is bottlenecking. More params is an easyish way to capture more knowledge if you have the architecture and the $$... but there are a lot of other techniques available that increase the efficiency of the parameters.
dwarfarchist9001 t1_j9lb1wl wrote
Yes but how many parameters must you actually have to store all the knowledge you realistically need. Maybe a few billion parameters is enough to store the basics of every concept known to man and more specific details can be stored in an external file that the neural net can access with API calls.
gelukuMLG t1_j9lfp3j wrote
You mean like a LoRA?
Viewing a single comment thread. View all comments