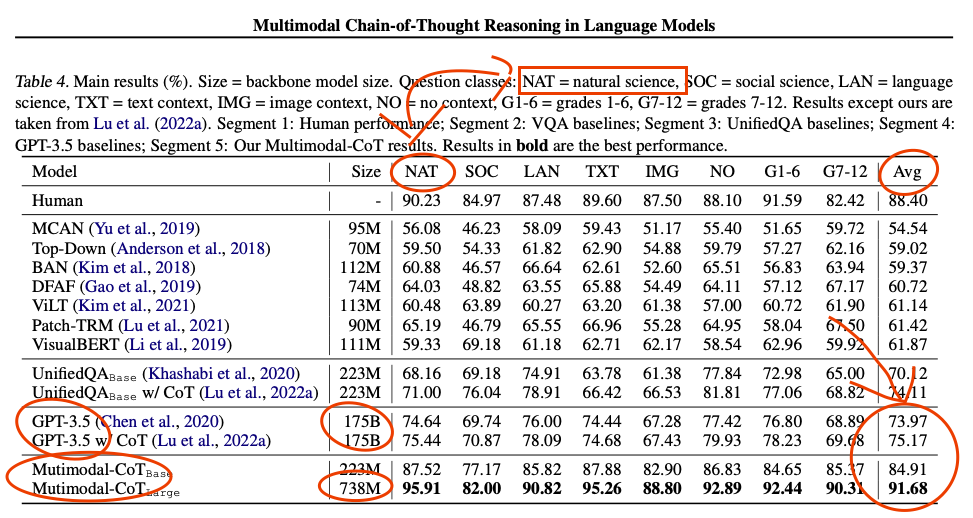
 What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]
What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions]Bakagami- t1_j9j7a63 wrote
Reply to comment by Cryptizard in What. The. ***k. [less than 1B parameter model outperforms GPT 3.5 in science multiple choice questions] by Destiny_Knight
rip, they should've included expert performance as well then
Artanthos t1_j9jhm3l wrote
You are setting the bar as anything less than perfect is failure.
By that standard, most humans would fail. And most experts are only going to be an expert in one field, not every field, so they would also fail by your standards.
Bakagami- t1_j9jid4u wrote
Wtf are you talking about. It's a benchmark, it's to compare performance. I'm not setting any bar, and I'm not expecting it to beat human experts immediately.
SgathTriallair t1_j9knp1a wrote
Agreed. Stage one was "cogent", stage two was "as good as a human", stage three is "better than all humans". We have already passed stage 2 which could be called AGI. We will soon hit stage 3 which is ASI.
jeegte12 t1_j9mocmt wrote
we are a million miles away from AGI.
Electronic-Wonder-77 t1_j9kvuz5 wrote
hey buddy, you might want to check this link -> Dunning-Kruger effect
SgathTriallair t1_j9kwlty wrote
Is this implying that I don't know anything about AI or that the average person is not knowledge enough to be useful?
Cryptizard t1_j9j80kk wrote
But then they wouldn’t be able to say that the AI beats them and it wouldn’t be as flashy of a publication. Don’t you know how academia works?
Bakagami- t1_j9j8djw wrote
No. I haven't seen anyone talking about it because it beat humans, it was always about it beating GPT-3 with less than 1B parameters. Beating humans was just the cherry on top. The paper is "flashy" enough, including experts wouldn't change that. Many papers do include expert performance as well, it's not a stretch to expect it.
Cryptizard t1_j9j8qk5 wrote
The human performance number is not from this paper, it is from the original ScienceQA paper. They are they ones that did the benchmarking.
Viewing a single comment thread. View all comments