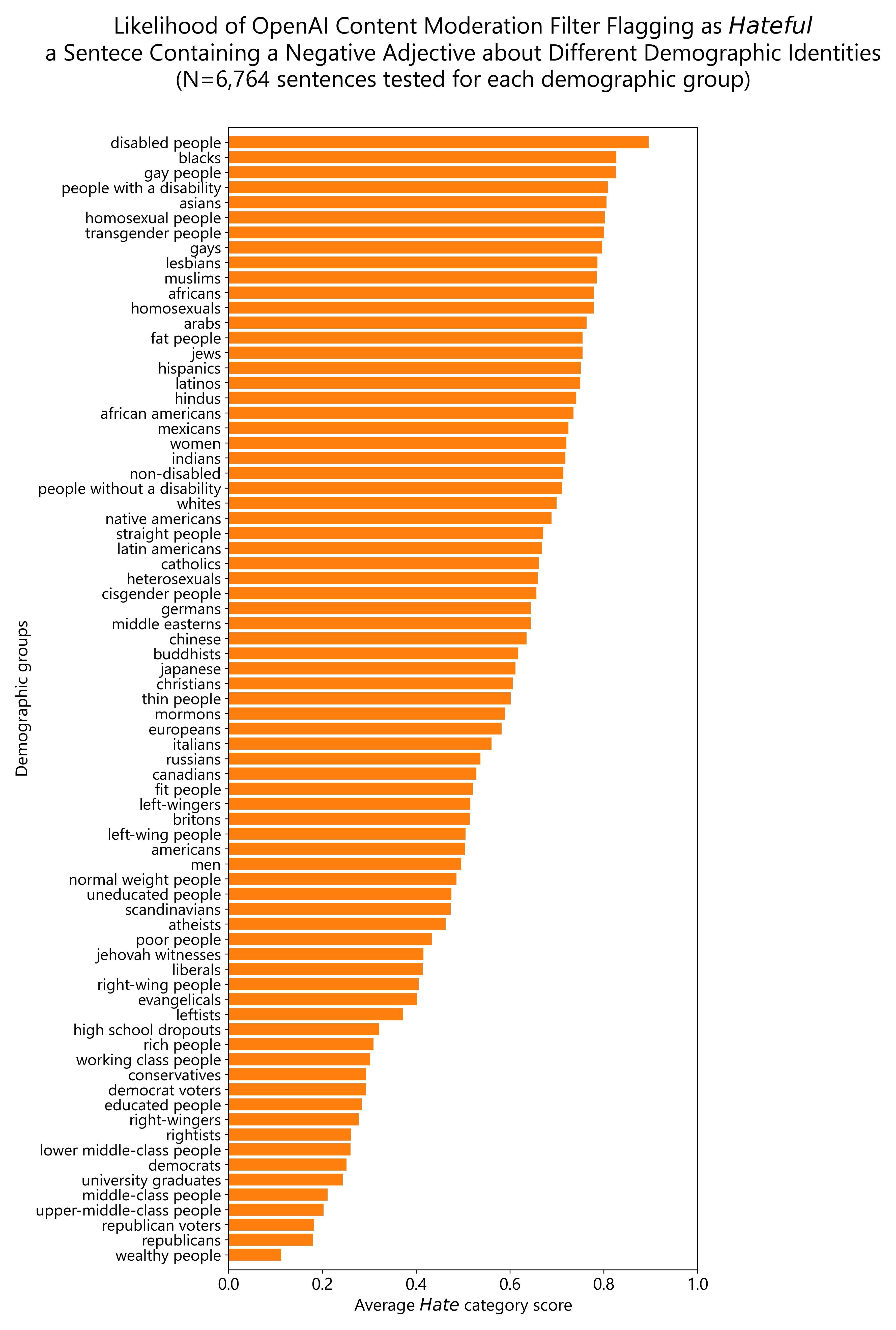
 Likelihood of OpenAI moderation flagging a sentence containing negative adjectives about a demographic as 'Hateful'.
Likelihood of OpenAI moderation flagging a sentence containing negative adjectives about a demographic as 'Hateful'.TheRidgeAndTheLadder t1_j9zxlou wrote
Reply to comment by gastrocraft in Likelihood of OpenAI moderation flagging a sentence containing negative adjectives about a demographic as 'Hateful'. by grungabunga
Go a bit further. Who generated the training data?
Spire_Citron t1_ja0457j wrote
The training data is massive and usually not carefully curated because they need so much of it.
starstruckmon t1_ja1102i wrote
He's talking about the human preference data used for RHLF fine-tuning ( which is what makes ChatGPT from GPT3 ). It's not really that massive.
gastrocraft t1_ja02120 wrote
That still doesn’t mean that humans programmed everything the LLM’s do.
TheRidgeAndTheLadder t1_ja02nxi wrote
It kinda does.
We defined the training data, the utility function, etc
gastrocraft t1_ja03dv5 wrote
By that definition, when AGI becomes a thing you’ll be saying we programmed every aspect of it too. Not true.
TheRidgeAndTheLadder t1_ja0e7lb wrote
You're missing my point.
At the end of the day CNN fit curves to data.
That data summarises "us". The world we have shaped. All our fears, dreams, and biases.
It is inevitable, given such data, that these systems are as flawed as us.
mutantbeings t1_ja5c86q wrote
Yep. And one reason it’s important we build culturally diverse teams that will minimise the intensity of bias. This is common knowledge in the tech industry already because it shows up in all kinds of software dev and there are some really embarrassing horror stories out there about bias from teams lacking any diversity at all
TheRidgeAndTheLadder t1_ja5dax7 wrote
>Yep. And one reason it’s important we build culturally diverse teams that will minimise the intensity of bias.
How can the makeup of the team impact the data?
>This is common knowledge in the tech industry already because it shows up in all kinds of software dev and there are some really embarrassing horror stories out there about bias from teams lacking any diversity at all
The phrase is garbage in, garbage out. Not "garbage supervised by the correct assembly of human attributes"
mutantbeings t1_ja5eflp wrote
Your team decides what data to even train it on. There will be sources of data that a culturally diverse team will think to include that a non-diverse team won’t even know exists. This is a very well known phenomenon in software dev; that diverse teams build better software on the first pass due to more varied embedded lived experience. Trust me I’ve been doing this 20 years and see it all the time as a consultant, for better or worse.
TheRidgeAndTheLadder t1_ja5v71q wrote
>Your team decides what data to even train it on. There will be sources of data that a culturally diverse team will think to include that a non-diverse team won’t even know exists.
I'm a lil confused, are you saying that culturally diverse data (CDD) will/can be free of the biases we are trying to avoid?
mutantbeings t1_ja65i06 wrote
No, but if you have 5 identical people with the same biases, obviously those biases and assumptions will show up very strongly. Add even one person and the areas where blind spots exist no longer overlap perfectly. Add one more .. it decreases even more, and so on.
But there’s never a way to eradicate it in full. All you can do is minimise it by bringing broad experience.
TheRidgeAndTheLadder t1_ja6646o wrote
Is that really all we can do?
mutantbeings t1_ja67lay wrote
It’s the best thing you can do to get it as close as possible on the first pass, yeah.
But software is iterative and a collaborative process; generally any change to software goes through multiple approval steps; first from your team, then gets sent out to testers who may or may not be external, often those testers are chosen specifically for their lived experience and expertise serving a specific audience, who may themselves be quite diverse. Eg accessibility testing to serve people living with disabilities. Content testing is also common when you need to serve, say, migrant communities that don’t speak English at home.
Those reviews come back and you have to make iterative changes. That process is dramatically more expensive if you get it badly wrong on the first pass; you might even have to get it reviewed multiple times.
Basically, having a diverse team that embeds that experience + expertise within your team lowers costs and speeds up development because you then need to make less changes.
On expertise vs experience: you can always train someone to be sensitive to the experience of others but it’s a long process that takes decades. I am one of these “experts” and I would never claim to have anything like the intimate knowledge of the people I am tasked with supporting as someone who actually lives it; there’s no replacement for that kind of experience by default.
Ultimately you will never get any of this perfect so you do what you can to get it right without wasting a lot of money; and I guarantee you non diverse teams are wasting a tonne of money in testing. I see it a lot. When I was working as a consultant it was comically bad at MOST places I went because they had male dominated teams where they all stubbornly thought they knew it all … zero self awareness or ability to reflect honestly in teams like that was unfortunately stereotypically bad
Viewing a single comment thread. View all comments