Submitted by terrykrohe t3_z42ub4 in dataisbeautiful
Submitted by terrykrohe t3_z42ub4 in dataisbeautiful
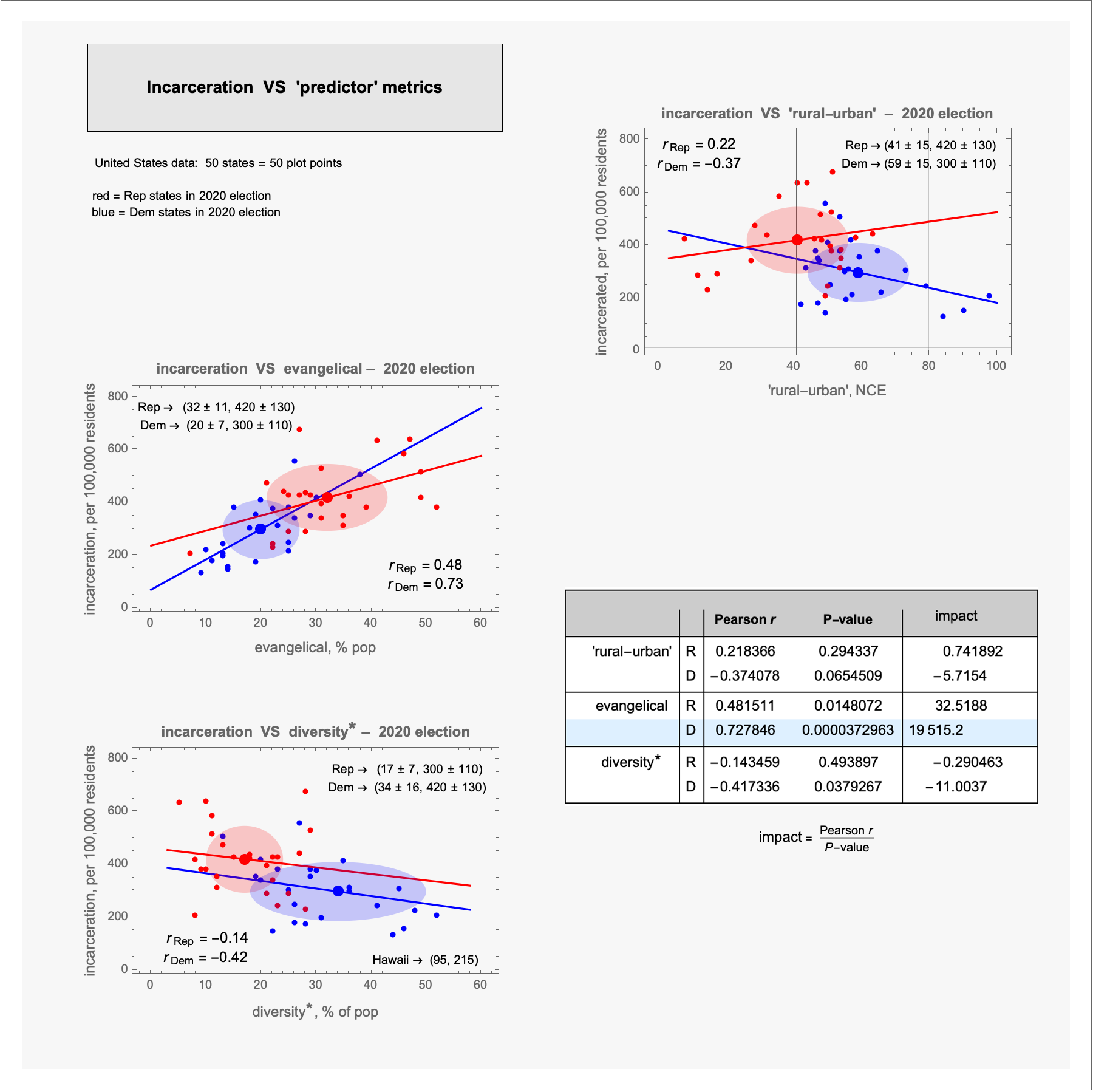
incarceration vs 'predictor' variables
I'm honestly glad you are looking to this data. However, you keep posting these scatter plots without any SUBSTANTIVE findings. In your explanatory text you said alot but didn't provide the actual SUBSTANTIVE findings. What did you learn about Repubs and Dems, incarceration and so on through this exercise?
It's like they're obsessed with plotting data and generating statistics but not in analyzing data or saying if their statistics rule out some kind of causation or hypothesis. How is the data 'beautiful' if it doesn't illuminate? Certain it's not because it's aesthetically pleasing. Maybe they're in competition for some sort of 'Spurious Correlations' award?
Ecological fallacy must be addressed for this correlative analysis to have value.
SUBSTANTIVE findings ...
1 – There is a non-random, top/bottom, Dem/Rep pattern.
2 – Rep states are always on the negative side.
3 – In all of the previous posts, there has been a nagging thought: Is there some way to quantify that some correlations are more important? The "impact" quantity does so (I think): the evangelical-incarceration correlation for the Dem states sticks out ... is this a one-time coincidence? ... will it be so for other 'response' metrics?
What did you learn about Repubs and Dems ...?
The truth of 1 and 2: Thanksgiving politics arguments are NOT just "my opinion, your opinion" – the Rep states are less productive, more obese, more suicidal, have less life expectancy, more infant mortality, more accidental deaths, receive more federal funds than they give in taxes, have a higher opioid dispensing rate, higher serious crime rate, spend less on education, have lower median incomes ... (most of the foregoing have been previously posted).
... jeez, the statistical improbability of "150 million voters, acting individually, separate(ing) the fifty states into two such disparate groups" is just plain awe-fully "mysterious".
(The most beautiful thing we can experience is the mysterious. It is the source of all true art and science. He to whom the emotion is a stranger, who can no longer pause to wonder and stand wrapped in awe, is as good as dead; his eyes are closed.)
Hi terrykrohe,
It looks like your comment closely matches the famous quote:
"The most beautiful experience we can have is the mysterious. It is the fundamental emotion that stands at the cradle of true art and true science." - Albert Einstein,
I'm a bot and this action was automatic Project source.
I am not convinced . Theses results are low, also you should provide more data such as variance and average.
It's lacking in drawing any significant statistic.
And if you are trying to prove the actual lack of correlation, the amount is still insufficient.
I don't know how to read any of that.
Yep. There you go. Very nicely done. On another note: Did you need to munger together a bunch of data for this? What sources did you use?
I was a little hard on the OP, but they nailed it....
Red states are more obese, less productive, more incarcerating, and so on...Really great stuff.
Well that is just because it is not well designed.
Let me get it straight for you.
The p-value expresses how likely a value is regarding the null hypothesis ( everything is random )
The pearson tell you how correlated two variables are.
His weird indicator divides the pearson by the p value which is ... not good. His value indicate that there is a high chance there is an effect in some cases but the pearson indicates the effect is minimal.
But we lack significance of data.
A meh but usable pearson is over 0.70, a good p value is under 0.1.
He barely got both for the definition of one category. Meaning there is one category where his predictor works sorta well and can be considered not random.
This is due to bivariate analysis on an obviously more complex problem.
He should include other indicator and try to show a correlation ( a multivariate analysis )
He also should try to do some PCA to understand better where the variance come from.
What sources did you use?
... see post 14Apr22 which presents the chosen response metrics data with source citations
... FYI, "missing persons" has a random pattern (posted 28Oct21)
what does the lines signify ?
... the lines are the "best-fit" lines through the data
– a mathematical visual to approximate the relationship of the variables, in this case, the predictor metric and incarceration rate relationship for Rep and Dem states
[deleted] t1_ixoy1da wrote
[removed]