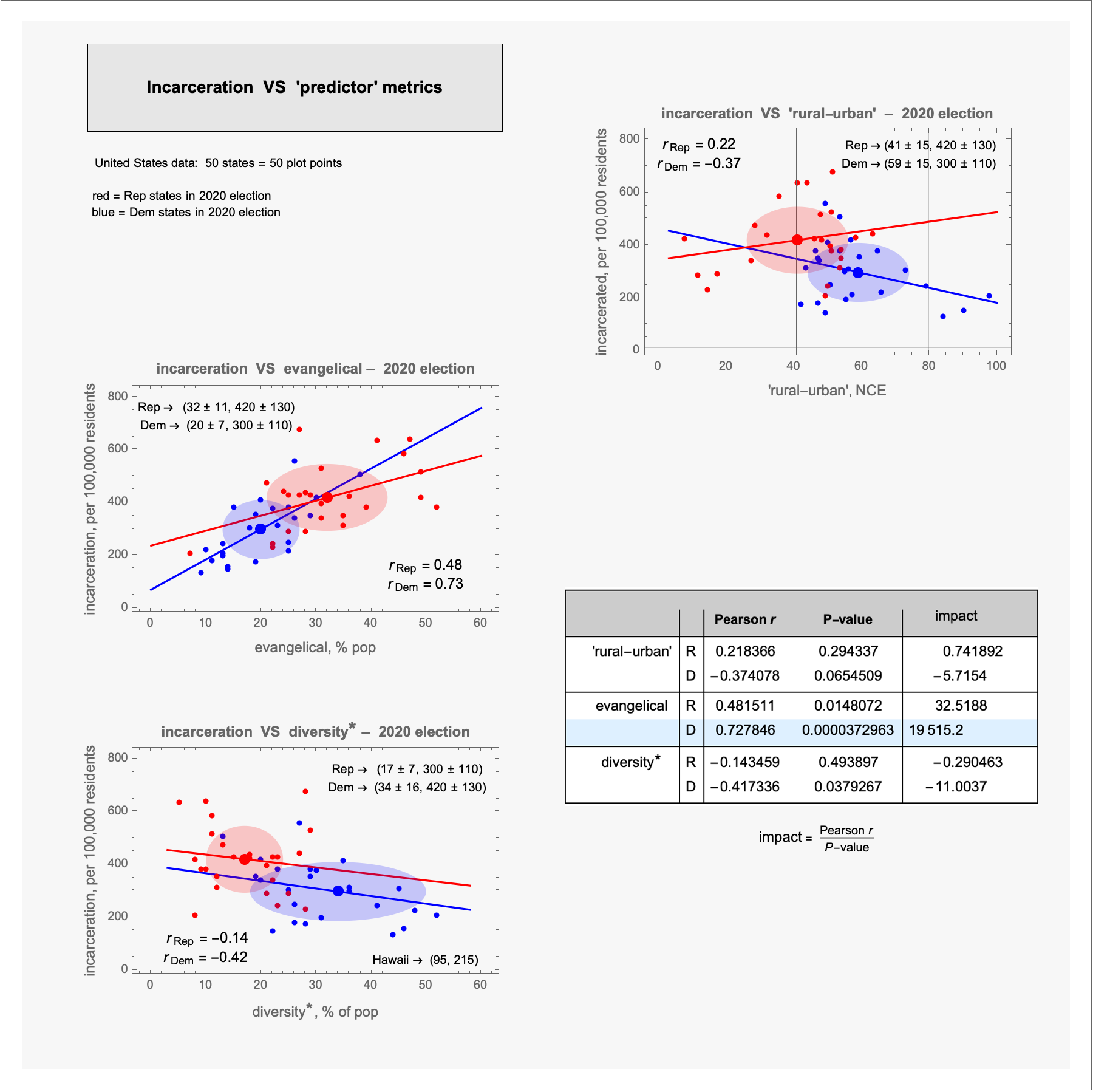
 [OC] incarceration vs 'predictor' metrics – 2020 election
[OC] incarceration vs 'predictor' metrics – 2020 electionSubmitted by terrykrohe t3_z42ub4 in dataisbeautiful
Datascientist-Player t1_ixr37xy wrote
Reply to comment by Purplekeyboard in [OC] incarceration vs 'predictor' metrics – 2020 election by terrykrohe
Well that is just because it is not well designed.
Let me get it straight for you.
The p-value expresses how likely a value is regarding the null hypothesis ( everything is random )
The pearson tell you how correlated two variables are.
His weird indicator divides the pearson by the p value which is ... not good. His value indicate that there is a high chance there is an effect in some cases but the pearson indicates the effect is minimal.
But we lack significance of data.
A meh but usable pearson is over 0.70, a good p value is under 0.1.
He barely got both for the definition of one category. Meaning there is one category where his predictor works sorta well and can be considered not random.
This is due to bivariate analysis on an obviously more complex problem.
He should include other indicator and try to show a correlation ( a multivariate analysis )
He also should try to do some PCA to understand better where the variance come from.
Cheap-Independent-39 t1_ixynb8x wrote
what does the lines signify ?
terrykrohe OP t1_iy2e02h wrote
... the lines are the "best-fit" lines through the data
– a mathematical visual to approximate the relationship of the variables, in this case, the predictor metric and incarceration rate relationship for Rep and Dem states
Viewing a single comment thread. View all comments