Submitted by orgtre t3_xujlqk in dataisbeautiful
Submitted by orgtre t3_xujlqk in dataisbeautiful
No idea what it means, too cryptic
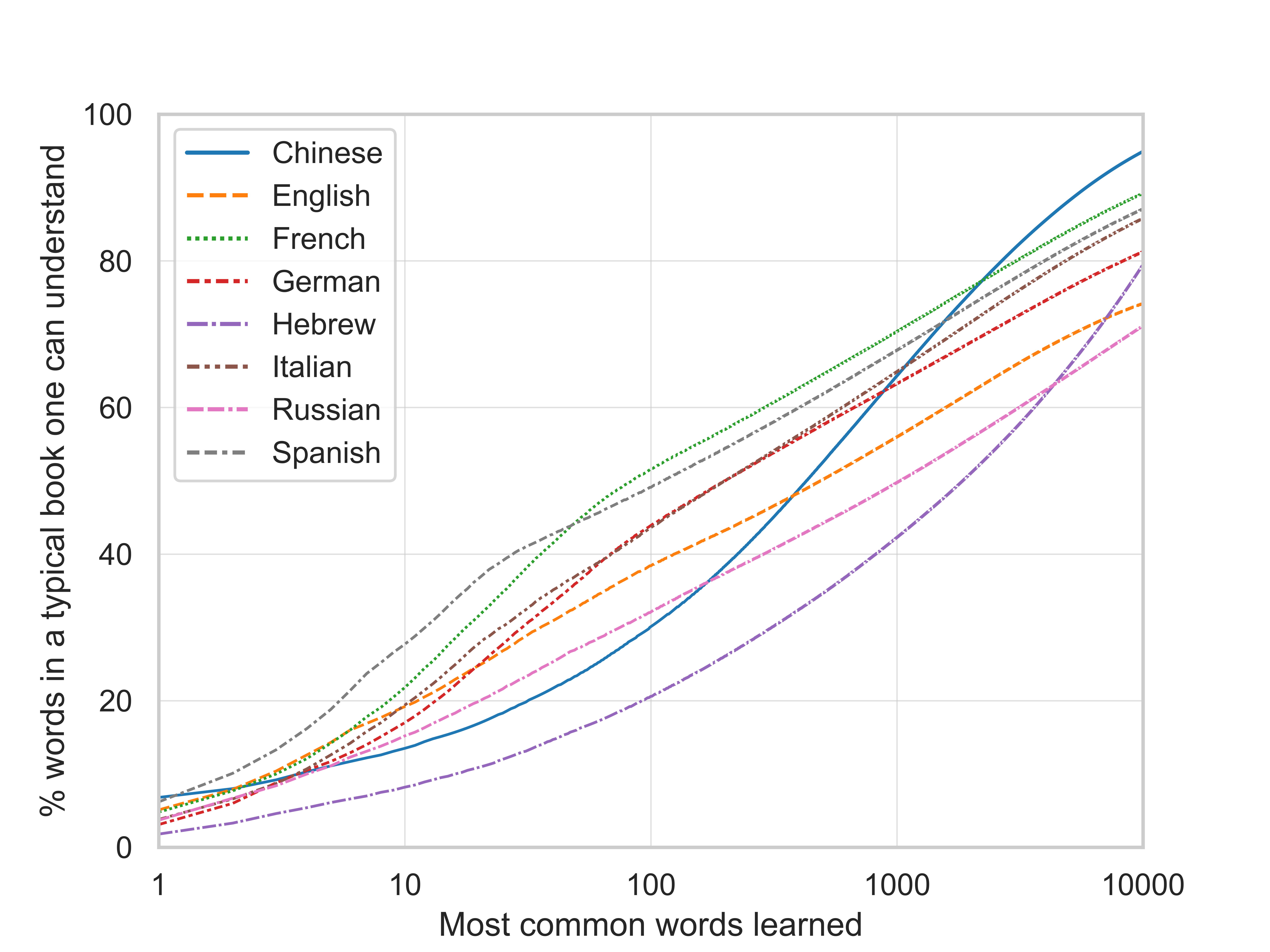
Maybe an example makes it more clear: After learning the 1000 most frequent French words, one can understand more than 70% of all words, counted with duplicates, occurring in a typical book in the French Google Books Ngram Corpus.
“Returns to learning”….means exactly nothing to the average person. The TITLE is especially cryptic
And now the downvote because someone pointed out that the title is non informative….what a surprise
Sorry, not by me though. I kind of like the title as it's short while still being reasonably descriptive, but can change it if many people agree with you.
If I know 1 word in Chinese, I can understand 5-7% of a book???
If someone knows only the word 'I', they can understand ~13% of your comment. (If you take understanding in the very narrow sense this post is taking it.)
Interesting data! I’m a bit skeptical about the graph for Chinese language. It suggests that on average 95% of a book can be understood if one knows 10000 Chinese words. 95% seems a bit high to me. Is it possible that the analysis only took Chinese characters into account?
In Chinese, words are comprised of characters. So multiple words share the same characters. Thus, one might be familiar with all the characters a word is comprised of, but may not know the meaning of the word/the combination of characters.
Edit: I want to add that in Chinese writing there is no space between words like there is in English, so it is not as trivial to find the boundaries between words
There’s an interesting conversation to be had here on vocabulary vs. semantics, one that I’m not qualified to weigh in on! The analysis seems to suggest that knowing 100 French words will let you understand around half of the average French book, but does being able to parse the most common, repetitive words such as pronouns and articles (un, une, le, la, il, elle, etc.) really get you that far if you don’t know any of the (less repeated) verbs and nouns they’re referring to? Interesting analysis but I’d love to see the next level up: if you trained an AI on only 100 common French words, what would its translations of a passage back to English look like?
Probably yes then... all the lines are in quite distinct colors.
oh.....
by the way its interesting/ great graph👍
Yes, it is strange. The analysis takes words into account – here is the underlying wordlist. The words were created by Google and the process is described on page 12 of the revised online supplement of this paper as follows: > The tokenization process for Chinese was different. For Chinese, an internal CJK (Chinese/Japanese/Korean) segmenter was used to break characters into word units. The CJK segmenter inserts spaces along common semantic boundaries. Hence, 1-grams that appear in the Chinese simplified corpora will sometimes contain strings with 1 or more Chinese characters.
I think the problem is that the Chinese corpus is much smaller than the other corpora. A better way to create this graph might have been to only include words that occur at least once every say one million words, but this would have needed quite some code changes and I'm not sure it is better. Right now the count of the total number of words per language, the denominator in the y-axis, includes all "words".
Moreover, the Chinese corpus might be based on a more narrow selection of books than the other corpora, as a look at the list of most common 5-grams (sequences of 5 "words") reveals.
Ahhh so it was tokenized. That’s nice to hear. Thanks for the elaborate answer! :)
Also, if someone with knowledge of Chinese would glance through the source repo for any obvious problems, that would be very helpful!
Can I return the title of this graph? I received it in an intelligible language.
Where did the data on the most common words/language come from? The same books as you used in your comparison?
In other words, if I used similar methods on a bunch of statistics textbooks, would I show high levels of comprehensibility with relatively small vocabularies based disproportionately on statistical jargon?
[removed]
As I understand it, this is basically a graph of how diverse the vocabulary of any given language is?
>95% seems a bit high to me
Not only is 10 000 words huge, but 5 % of unknown words is enough to make a text cryptic to the point where it's barely readable.
4 % unknown words: Yesterday in the morning, I went to the ???????, as I like to do every Monday. I'm a regular customer there.
Exactly. To clarify: The original comment has 15 "words" (Google counts "," as a separate word...), 2 of which are "I", and 2/15 is around 13%.
The most common Chinese word is "的", which Google translates as "of", and at least in Google's selection of books it makes up 7% of all words.
Yes, the data comes from the same books. For each language I create an ordered list of the most frequent words, looking like this. The graph then just plots the rank of the word on the x-axis and the cumulative relative frequency (column "cumshare" in the csv files) on the y-axis.
The answer to your last question is hence also yes. It brings up the question of how representative the underlying corpus is. I wrote a bit about that here and there is also this paper. To be very precise the y-axis title should be "% words in a typical book from the Google Books Ngram corpus one can understand"; to the extent that one thinks the corpus is representative of a typical book one might read, the "from the Google Books Ngram corpus" part can be omitted.
This is probably why Hebrew scores so poorly on this metric. Many of these kinds of articles and conjunctions are added to the word with a prefix character. Like:
אבא - father
האבא - the father
But it’s not as if it’s any harder to spot the hebrew -ה than it is to spot the english “the” just because it’s a prefix rather than its own word…
Spanish has always seemed like a much simpler language than English to me and it's interesting to see this data sort of confirm that.
I feel like the Spanish speakers use way less vocabulary and slang than English speakers. I expect that spoken Spanish is a much more efficient language than spoken English at efficiently conveying simple communications, but that English is a much more efficient language than Spanish at conveying complex communications.
If I had to teach an Alien race to communicate with humans, I'd teach them Spanish.
If I had to teach an Alien race how to write good novels, I'd teach them English.
This checks out. After my third semester studying Russian, I'd talk to friends learning other languages: "Oh, we're reading Don Quixote or The Three Musketeers, how about you?" "Yeah, I'm reading a nursery rhyme about a speckled chicken."
Fuck, it's been 30 years and I think I still have a bit of it memorized: "жили были дед да баба. была у них курочка ряба..."
Yes, basically. But in addition to differences in vocabulary diversity, differences between the lines of different languages might be due to differences in the collections of books (corpora) these lines are based on.
On thing that seems to play a role is that the corpora are of different sizes: Lines for both Hebrew and Chinese look quite different from the other languages, and these corpora are also much smaller than the others. Hebrew and Chinese both also use a non-Roman alphabet, but so does Russian, whose corpus is larger. So this is some indication of that Hebrew and Chinese stand apart because of their smaller corpus size.
Just an observation: the lists seem to indicate that the Chinese corpus is largely based on recent government documents/reports and legal codes that are published in book form. I would guess even if one understands the meaning of every word on the 1-grams list, one would still find reading a relatively accessible classical Chinese novel (like the Romance of the 3 Kingdoms) a bit difficult.
[removed]
You've certainly heard of the "law of diminishing returns"? It means that there's a point where you have to put a lot more effort to get only a little more profit out of something, so eventually it just stops being worth it and you stop trying to improve your process.
"Return" is what you get out of something. In this case, "returns to learning" means "what you get out of your efforts if you learn whatever amount of words".
Maybe it's not a familiar expression for you, but it's a concise way to convey that very specific idea.
Keep in mind that this subreddit is about data and their graphical representation. "Returns" are a familiar concept to many people here and to pretty much anybody who knows about data.
I don't think it's cryptic, u/ortgre.
The title is unclear. You just spent how many words to explain a TITLE, does that not suggest it is cryptic? No one mentioned the graph itself….
Your not thinking it is cryptic does not discount that other people find it cryptic. Your opinion is equal to any others, no more-no less.
The title COULD have been “Minimum number of words needed to be learned to be able to read a book in a foreign language”. Longer, sure but also much clearer as to intent
I used a lot of words to explain it to you, because you didn't understand. Many other people didn't need the explanation. And your opinion seems to be the minority, seeing how most comments focus on the graph itself.
crosspost to r/ language learning
orgtre OP t1_iqvqi5z wrote
This was created from the Google Books Ngram Corpus Version 3 using Python (seaborn/matplotlib). The code is available in this repository. It's a simple-looking graph but it is based on the analysis of hundreds of billion words!