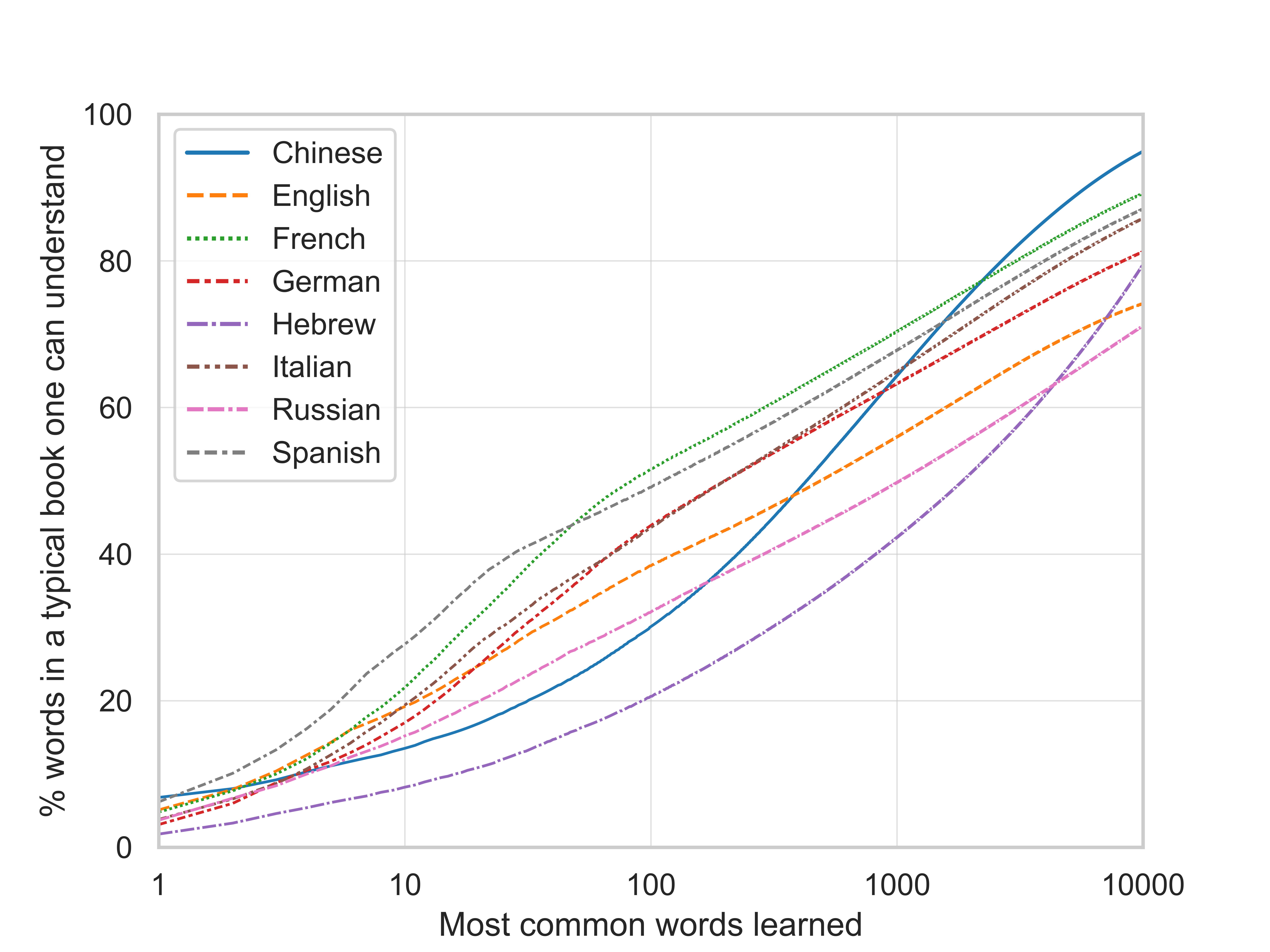
 The returns to learning the most common words, by language [OC]
The returns to learning the most common words, by language [OC]Submitted by orgtre t3_xujlqk in dataisbeautiful
orgtre OP t1_iqx4i2s wrote
Reply to comment by draypresct in The returns to learning the most common words, by language [OC] by orgtre
Yes, the data comes from the same books. For each language I create an ordered list of the most frequent words, looking like this. The graph then just plots the rank of the word on the x-axis and the cumulative relative frequency (column "cumshare" in the csv files) on the y-axis.
The answer to your last question is hence also yes. It brings up the question of how representative the underlying corpus is. I wrote a bit about that here and there is also this paper. To be very precise the y-axis title should be "% words in a typical book from the Google Books Ngram corpus one can understand"; to the extent that one thinks the corpus is representative of a typical book one might read, the "from the Google Books Ngram corpus" part can be omitted.
Viewing a single comment thread. View all comments