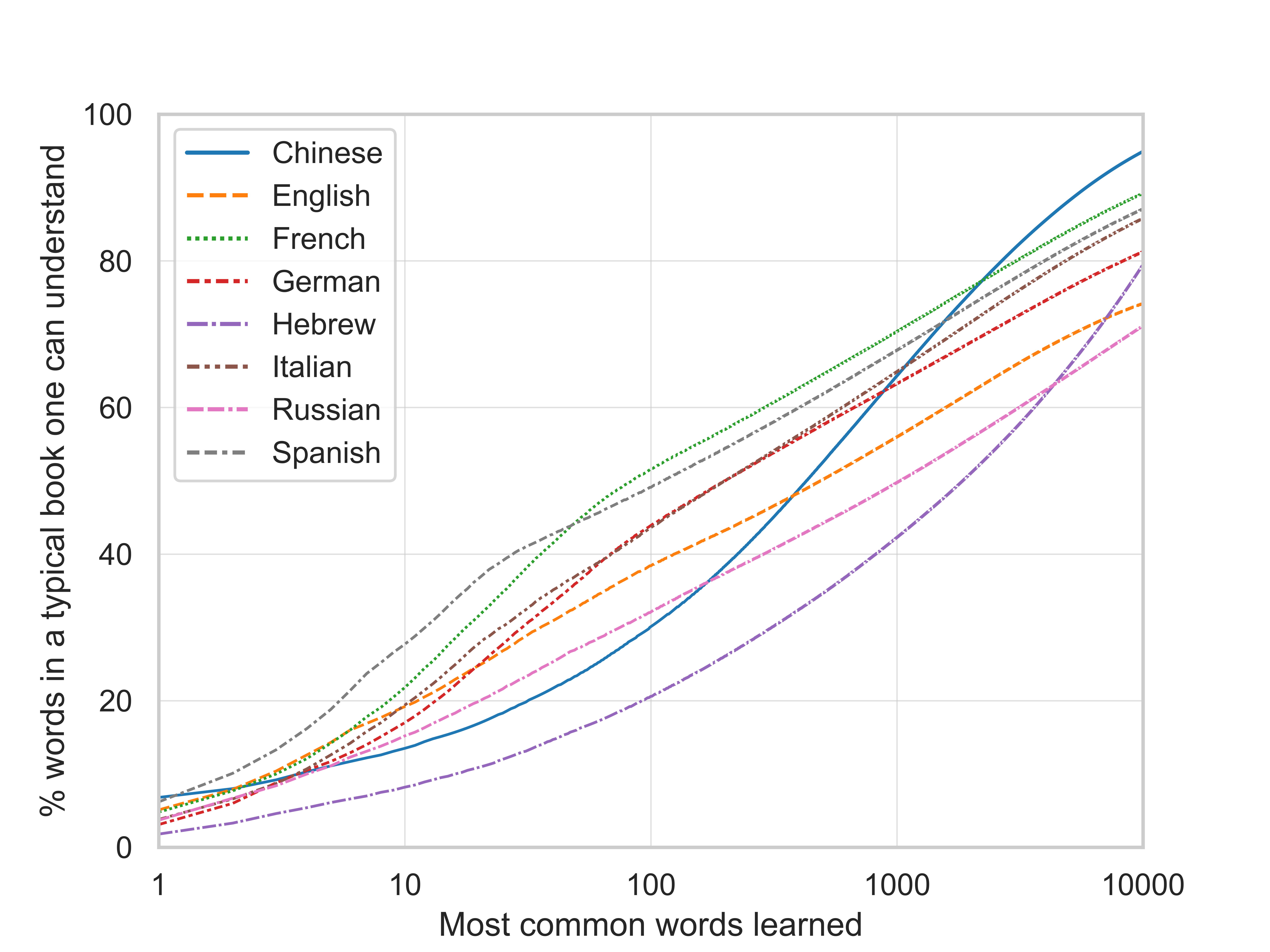
 The returns to learning the most common words, by language [OC]
The returns to learning the most common words, by language [OC]Submitted by orgtre t3_xujlqk in dataisbeautiful
RedditSuggestion1234 t1_iqwn1vb wrote
As I understand it, this is basically a graph of how diverse the vocabulary of any given language is?
orgtre OP t1_iqxdr8t wrote
Yes, basically. But in addition to differences in vocabulary diversity, differences between the lines of different languages might be due to differences in the collections of books (corpora) these lines are based on.
On thing that seems to play a role is that the corpora are of different sizes: Lines for both Hebrew and Chinese look quite different from the other languages, and these corpora are also much smaller than the others. Hebrew and Chinese both also use a non-Roman alphabet, but so does Russian, whose corpus is larger. So this is some indication of that Hebrew and Chinese stand apart because of their smaller corpus size.
Viewing a single comment thread. View all comments