 The returns to learning the most common words, by language [OC]
The returns to learning the most common words, by language [OC]Submitted by orgtre t3_xujlqk in dataisbeautiful
nic333rice t1_iqw529i wrote
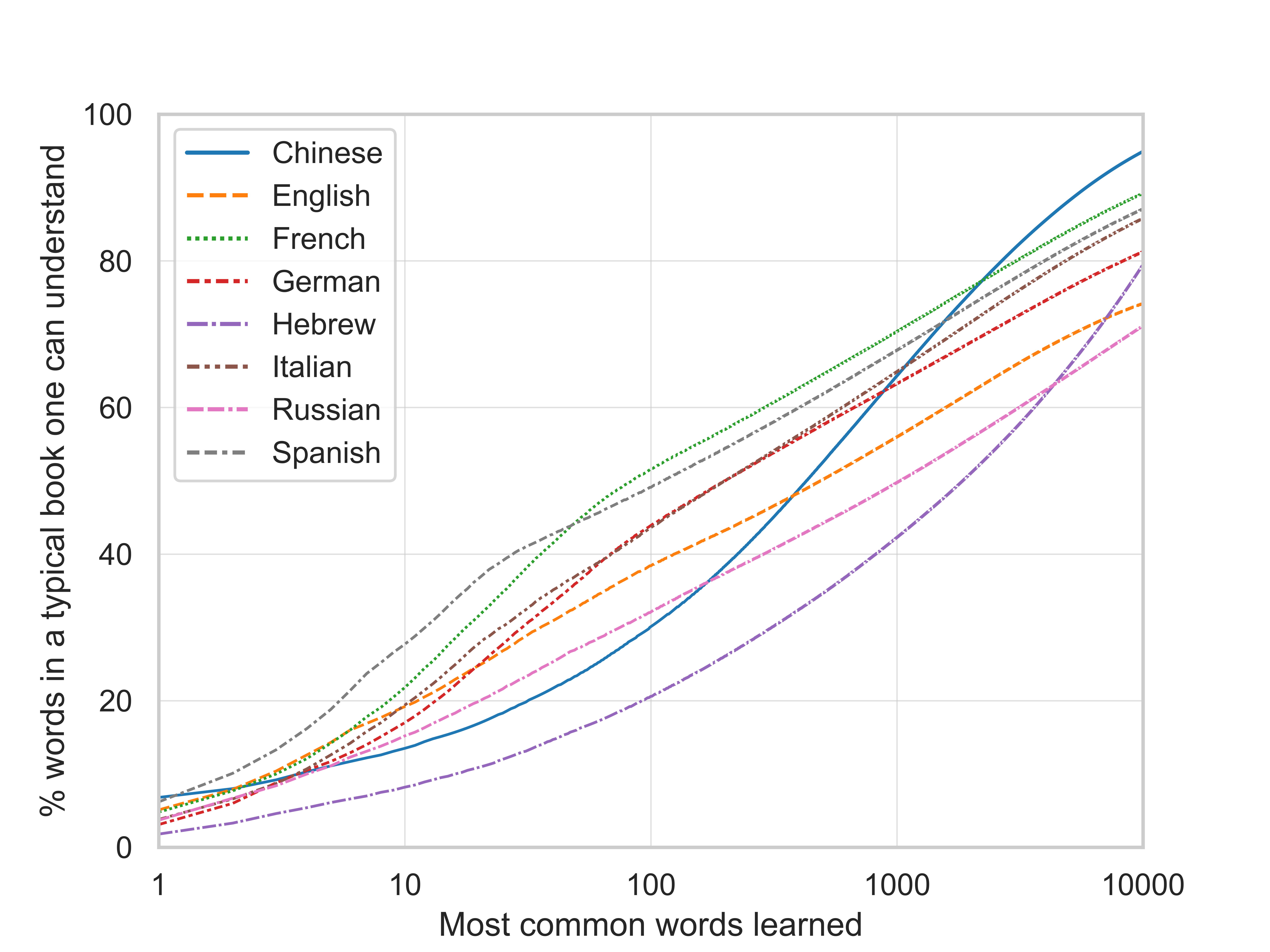
Interesting data! I’m a bit skeptical about the graph for Chinese language. It suggests that on average 95% of a book can be understood if one knows 10000 Chinese words. 95% seems a bit high to me. Is it possible that the analysis only took Chinese characters into account?
In Chinese, words are comprised of characters. So multiple words share the same characters. Thus, one might be familiar with all the characters a word is comprised of, but may not know the meaning of the word/the combination of characters.
Edit: I want to add that in Chinese writing there is no space between words like there is in English, so it is not as trivial to find the boundaries between words
RedditSuggestion1234 t1_iqwnwly wrote
>95% seems a bit high to me
Not only is 10 000 words huge, but 5 % of unknown words is enough to make a text cryptic to the point where it's barely readable.
4 % unknown words: Yesterday in the morning, I went to the ???????, as I like to do every Monday. I'm a regular customer there.
orgtre OP t1_iqwcedp wrote
Yes, it is strange. The analysis takes words into account – here is the underlying wordlist. The words were created by Google and the process is described on page 12 of the revised online supplement of this paper as follows: > The tokenization process for Chinese was different. For Chinese, an internal CJK (Chinese/Japanese/Korean) segmenter was used to break characters into word units. The CJK segmenter inserts spaces along common semantic boundaries. Hence, 1-grams that appear in the Chinese simplified corpora will sometimes contain strings with 1 or more Chinese characters.
I think the problem is that the Chinese corpus is much smaller than the other corpora. A better way to create this graph might have been to only include words that occur at least once every say one million words, but this would have needed quite some code changes and I'm not sure it is better. Right now the count of the total number of words per language, the denominator in the y-axis, includes all "words".
Moreover, the Chinese corpus might be based on a more narrow selection of books than the other corpora, as a look at the list of most common 5-grams (sequences of 5 "words") reveals.
i875p t1_iqxk5mt wrote
Just an observation: the lists seem to indicate that the Chinese corpus is largely based on recent government documents/reports and legal codes that are published in book form. I would guess even if one understands the meaning of every word on the 1-grams list, one would still find reading a relatively accessible classical Chinese novel (like the Romance of the 3 Kingdoms) a bit difficult.
nic333rice t1_iqwd1f8 wrote
Ahhh so it was tokenized. That’s nice to hear. Thanks for the elaborate answer! :)
orgtre OP t1_iqwdfqy wrote
Also, if someone with knowledge of Chinese would glance through the source repo for any obvious problems, that would be very helpful!
Viewing a single comment thread. View all comments