Submitted by pommedeterresautee t3_10xp54e in MachineLearning
programmerChilli t1_j7toust wrote
Reply to comment by pommedeterresautee in [P] Get 2x Faster Transcriptions with OpenAI Whisper Large on Kernl by pommedeterresautee
> The Python layer brings most of the PyTorch latency.
This actually isn't true - I believe most of the per-operator latency come from C++.
pommedeterresautee OP t1_j7tp663 wrote
I guess you better know than me :-)
Which part? The dispatcher thing or it's spread on several steps?
programmerChilli t1_j7tpwd7 wrote
Lots of things. You can see a flamegraph here: https://horace.io/img/perf_intro/flamegraph.png (taken from https://horace.io/brrr_intro.html).
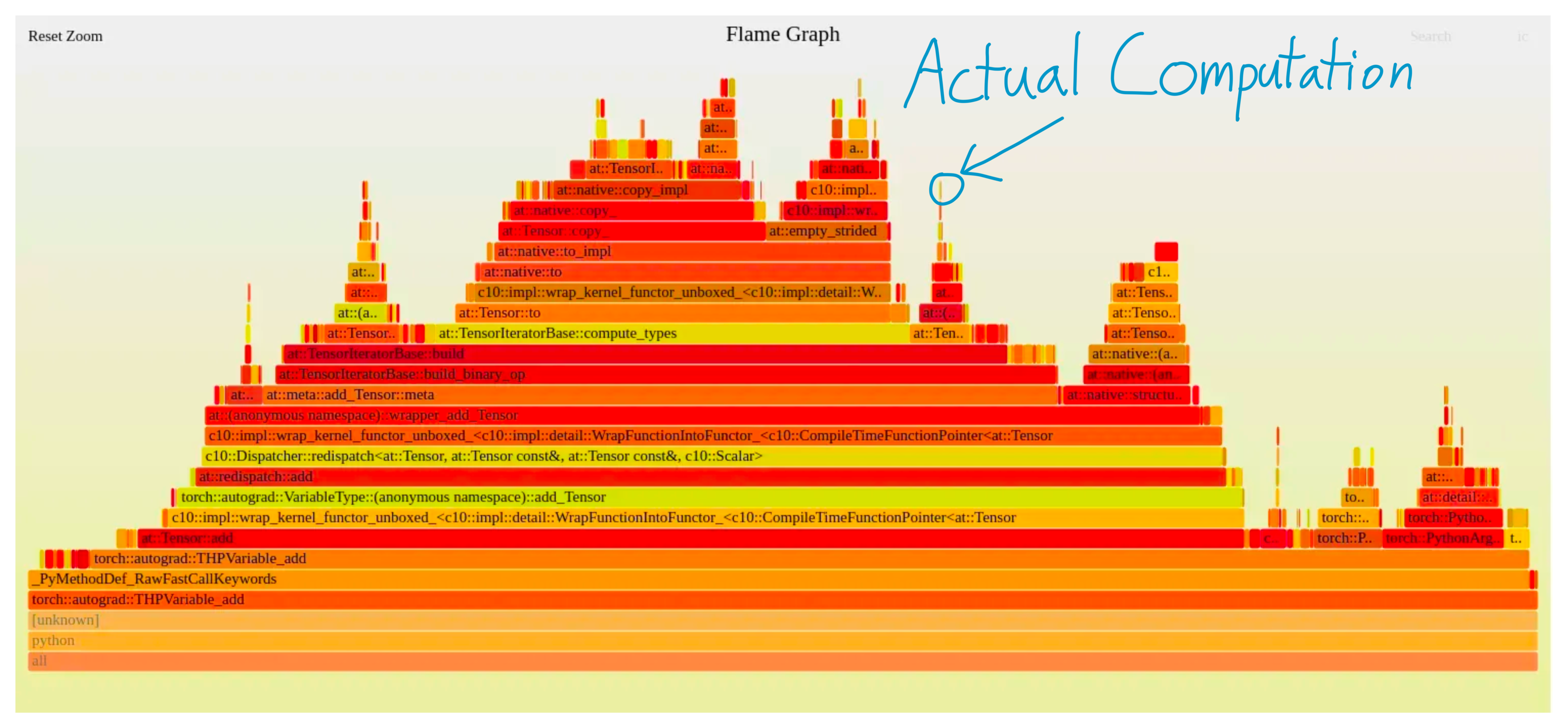{kind=link}
Dispatcher is about 1us, but there's a lot of other things that need to go on - inferring dtype, error checking, building the op, allocating output tensors, etc.
Viewing a single comment thread. View all comments