Submitted by michaelthwan_ai t3_11vi82q in MachineLearning
Submitted by michaelthwan_ai t3_11vi82q in MachineLearning
Can this use a SQL database as an external reference?
Look into llama-index
Thank you.
Due to people close to me and my googling, my choices of indexer is like this
pyterrier -> faiss -> native embedding
Then I found llama-index, but it currently won't give extra values to me so I didn't adopt.
I have stories on pros/cons on those lib...
Theoretically yes but in exact the objective you want to do is crucial.
SQL database don't support similarity/elastic search, which is very useful in natural language. It may limit what you can do or make your product less good.
This is completely false. Elastic was invented by SQL. You use things like “LIKE” and a few other choice keywords. Just google them or go to Microsoft directly and look at sql select statements. You can string together CTE’s which immediately gives you elasticity. So, sorry, but this is a nonsensical response
ChatGPT said what I want to say.
>I apologize for any confusion or misinformation in my previous response. You are correct that SQL databases do support various text search and similarity matching features, including the use of keywords like LIKE and CTE (Common Table Expressions) to enable more flexible and efficient querying.
>
>While it's true that specialized tools like Elasticsearch, Solr, or Algolia may offer additional features and performance benefits for certain natural language processing tasks, SQL databases can still be a powerful and effective tool for storing and querying structured and unstructured data, including text data.
>
>Thank you for bringing this to my attention and allowing me to clarify my previous response.
Not sure this is frontend problem or not, but the python code is printed without identation.
I believe it is a frontend problem. We are not frontend developers thus but we think that Gradio is too plain to show the result, thus we built a minimal UI.
That markdown (``` <code> ```) is currently not supported to pretty print like ChatGPT one.
If you can have it add a class and add "white-space: pre" to the css, it should probably fix it if it's just a frontend issue.
[removed]
[deleted]
Cool! Thanks for the sharing.
During my development, I've also found 5+ projects, some open-source and some are closed, where they are doing similar things.
In exact, it is called retrieval-based language model.
Some discussion on that:
Made a few issues and a pull request for changes in the source code adding support for DuckDuckGo. So if anyone willing to ditch Bing as a dependency and OpenAI(in the future) make sure to keep an eye on this project.
I liked the idea that it's all within a terminal. No need to open a browser and ask for questions. Pretty useful for searching without switching a cognitive context from a vim tab with the code to a browser. In december I did something similar with just a wrapper around OpenAI completion and was asking questions about coding. In combination with codequestion it was pretty useful. This one(XOXO) makes it a much pleasant experience.
​
Cheers!
someone had to do this as OSS MIT, great, thx!
Of course we do! Open-source projects are cool
Just like humans, LLMs learn patterns and relationships, not "facts" unless you make it memorize it by repeating training data over and over, but it makes other aspects of the system to degrade.
So, LLMs should be given all the tools humans use to augment their thought - spreadsheets, calculators, databases, CADs, etc and allow them to interface them quickly and efficiently.
I agree with you. 3 thoughts from me
- I think one direction of the so-called safety AI to give a genuine answer, is to give it factual/external info. I mean 1) a Retrieval-based model like searchGPT 2) API calling like toolformer (e.g. check weather API)
- LLM, is essentially a compression problem (I got the idea in lambdalabs). But it cannot remember everything. Therefore an efficient way to solve so are retrieval methods to search a very large space (like pagerank/google search), then obtain a smaller result set and let the LLM organize and filter related content from it.
- Humans are basically like that right? But if we got a query, we may need to read books (external retrieval) which is pretty slow. However, humans have a cool feature, long-term memory, to store things permanently. Imagine if an LLM can select appropriate things during your queries/chat and store them as a text or knowledge base inside it, then it is a knowledge profile to permanently remember the context bonded between you and the AI, instead of the current situation that ChatGPT will forget everything after a restart.
There is a problem with context length, but than given the fact that us humans have even less context length and can get carried away in conversation... I think 32kb context length is actually much greater leap in GPT4 than other metrics if you want it to tackle more complex tasks, but it is "double gated". Again, even humans have problems with long context even in pretty "undemanding" tasks like reading fiction, that's why books have chapters I presume :) Btw, anterograde amnesia is a good example how humans would look like w/o longterm memory, heh.
Anyway, I'm sure a set of more compact models trained on much more high-quality data is the way to go - or at least fine-tuned by high-quality data, coupled with APIs and other symbolic tools, and multimodality (sketches, graphs, charts) as input AND output is absolutely nessesary to have a system that can be more than "digital assistant".
Yeah great summary related to the memory.
My next target may be related to compact models (which preserve good results), as I also believe it is the way to go :D
Yea, I'm sure that compact-ish distilled, specialised models trained on high quality, multimodal data is the way to go.
What's interesting, once generative models get good enough to produce synthetic data that is OF HIGHER QUALITY than laion/common crawl/etc, it should improve model quality which should allow to generate better synthetic data... not exactly singularity, but certainly one aspect of it :)
Your idea sounds like GAN - maybe one model will generate high-quality synthetic data and another one try to 'discriminate' it, then they may output an ultra-high quality one finally (for another model to eat). And an AI model community is formed to self-improve...
Yea, in a way something like this was already done with LLAMA-Alpaca finetune - they used chatgpt to generate instuct finetune dataset, what, while far from pefrect, worked pretty damn well.
Looks dope
Very cool!
Thank you! :D
Google need to be worried
It is a little bit exaggerated but thanks! I believe Bing and some companies are using similar tech, but a highly polished one, to solve similar issues.
But you haven’t written a search engine????
haha. Nice point.
I'm not sure whether it fulfil the definition of a search engine, but this work essentially mimics your experiences during googling: Google->got n websites->surf and find info one by one.
SearchGPT (or e.g. new Bing) attempted to automate this process. (Thus Google is unhappy)
This looks great 👍
Shared to r/aipromptprogramming
Thank you!
Any chance you will add this as a Hugging Face Space?
whats the benefit?
Pros:
Cons:
Nice job
How many websites did you index in your search engine?
This is great !!!
Hi! Your project and other projects based on this topic constitute a valid response to active curiosity on this subject. It will be in the interest of society for AI-powered search engines to enter the active development process and gather their unique user base. The only doubt is that as OpenAI and other AI "for-profit" companies close their projects to external analysis and development over time (see GPT-4), AI-powered applications will become closed boxes and the development potential of these projects will be limited. The active protest reactions that we can show on this issue can lose its effect over time, the masses can close their eyes in the face of hype and demand products that are harmful to us in the long run. For this reason, I think that the protest in this area should be made as a mass as soon as possible.
I may have stretched the subject a bit too much, I liked your project and other similar projects quite a lot. Not only did it answer the test question I just asked, it also corrected my grammatical errors in the question, causing me to be a little surprised swh. My request is that we, as a society, do not forget about the potential that we are losing by getting immersed in leading projects. AI-powered applications are great, but we must not forget our rights that these companies take away from us day by day.
Thank you for your comprehensive input.
- I have mixed feeling about opening/closing the technology. There are pros/cons to it. For example, we, especially people in this field have a strong curiosity about how giant technology solves their problems (like chatgpt). Therefore open-sourcing them will bring us rapid development in related fields (like the current AI development). However, I also understand that, malicious usage is also highly possible when doing so. For example, switching the reward function from chatgpt model from positive to negative may make a safe AI into the worst AI ever.
- Humans seem to not be able to stop technological advancement. Those technologies will come sooner or later.
- Yes I agree to preserve our rights today and the society should carefully think about how to deal with this unavoidable (AI-powered) future.
Thanks for your reply. If technological developments are opened to the masses, as you said, the speed of development will jump. We're talking about a much higher rate of technological development than a closed development environment can provide. It will never reach its potential for development under the monopoly of companies that use technology and science like a cow for profit.
On the other hand, the current developments and potentials under the monopoly of these companies are more conducive to malicious use. The company, which, like OpenAI, was built on the axis of control and good purposes in the development of artificial intelligence, has now become Microsoft's cow. Microsoft, which fired the ethics team before the introduction of GPT-4, and similar companies prefer to use artificial intelligence to gain power and worship power in unethical ways from the very beginning.
Rather than protecting the public against a potential that could be used for malicious purposes, these companies may use this potential to serve "their" unethical purposes for their own profit. In this case, they turn into "bad guys" in order to prevent malicious people from using the technological potential for their own benefit.
Artificial intelligence and technological development potential should not be monopolized by anyone. In this way, we are responsible for raising awareness ourselves and raising the awareness of the masses by doing our part. The current hype should not blind people.
Encountered error You exceeded your current quota, please check your plan and billing details.
My first try .. I got an error:
Encountered error You exceeded your current quota, please check your plan and billing details.
added some credits to it . Used up all. I will monitor the usage
[deleted]
Added an "examples of prompts" on the top for showcases!
{kind=link}
michaelthwan_ai OP t1_jct4sdj wrote
Demo page: https://searchgpt-demo.herokuapp.com/
Github : https://github.com/michaelthwan/searchGPT
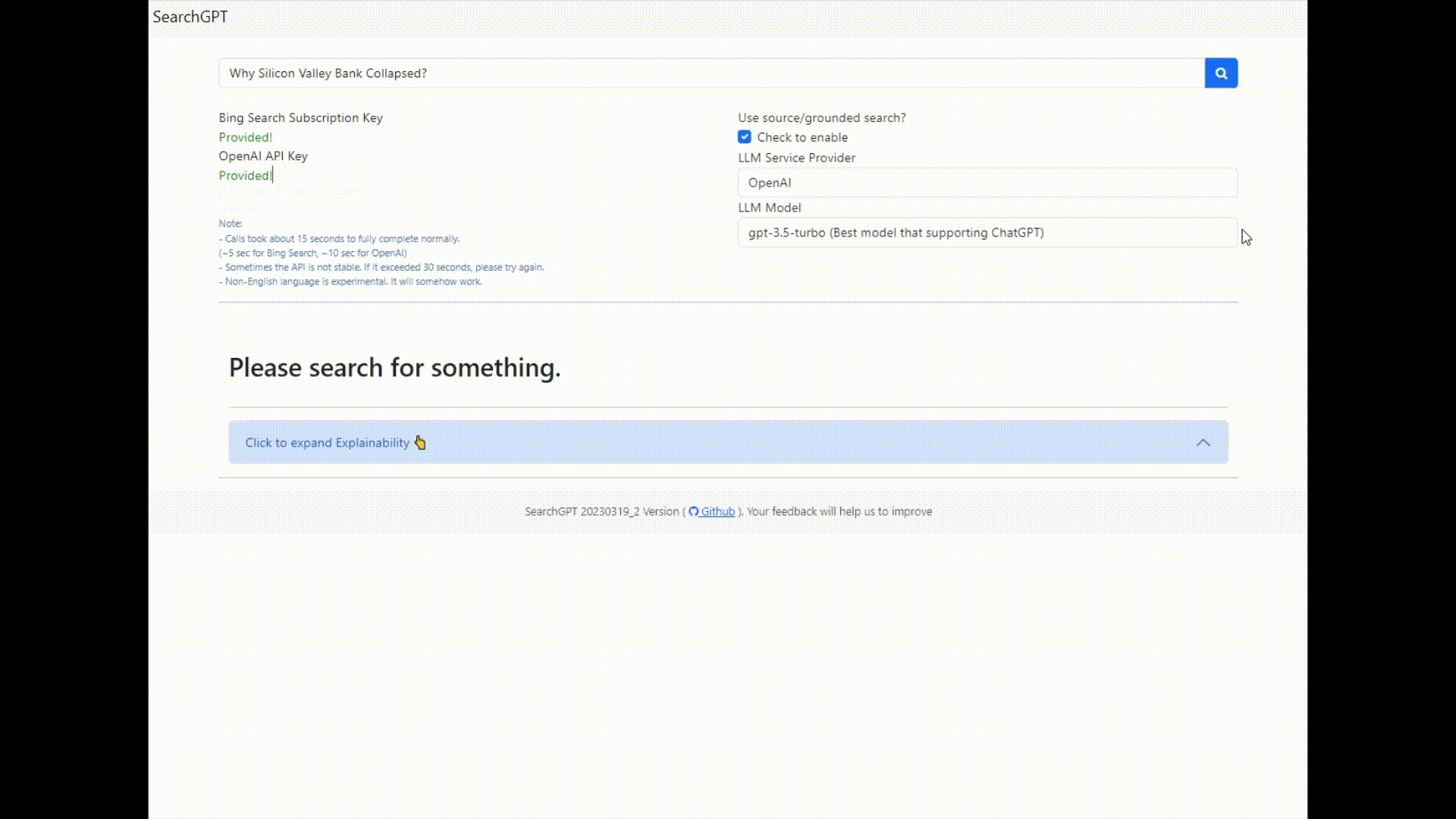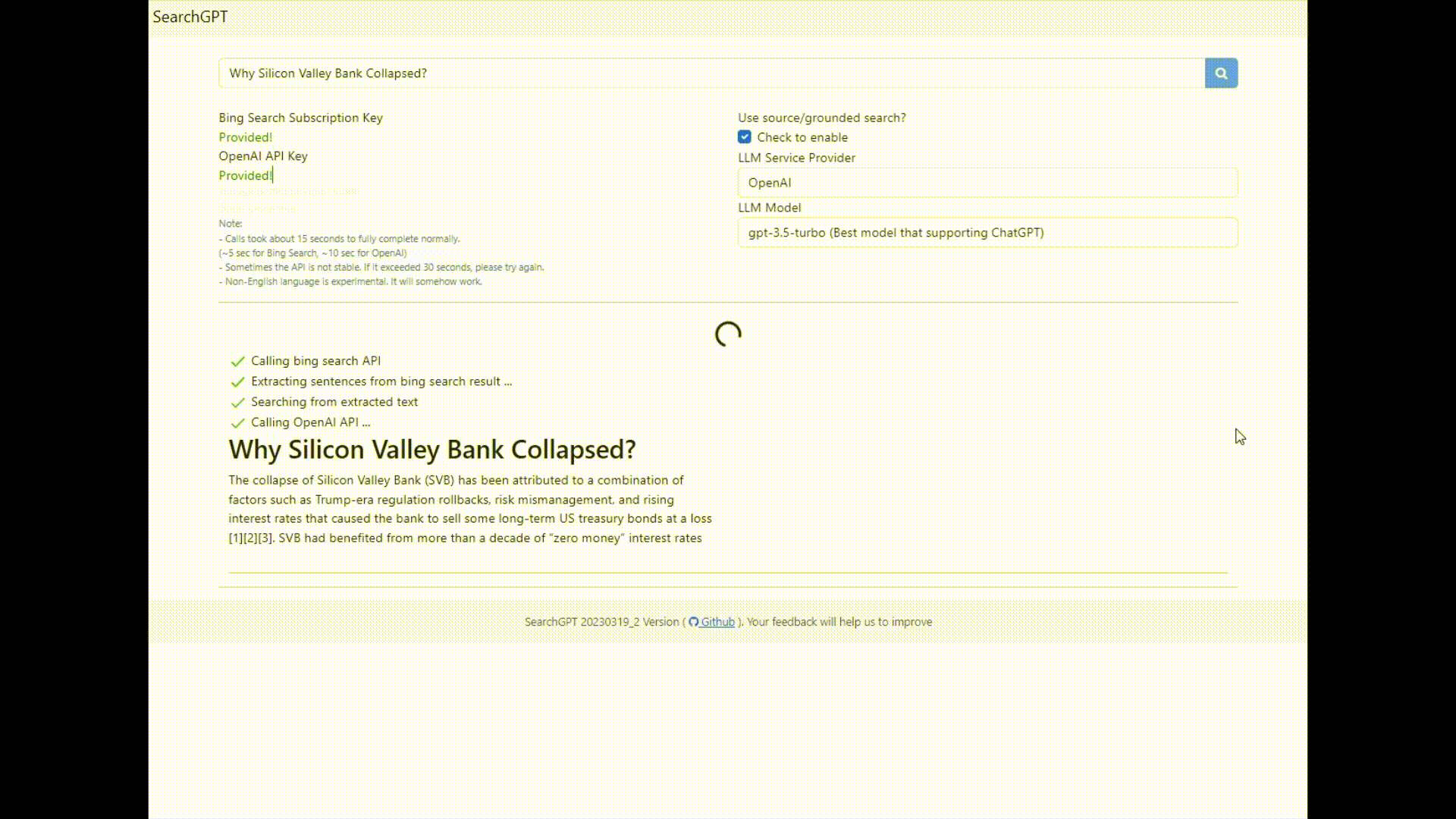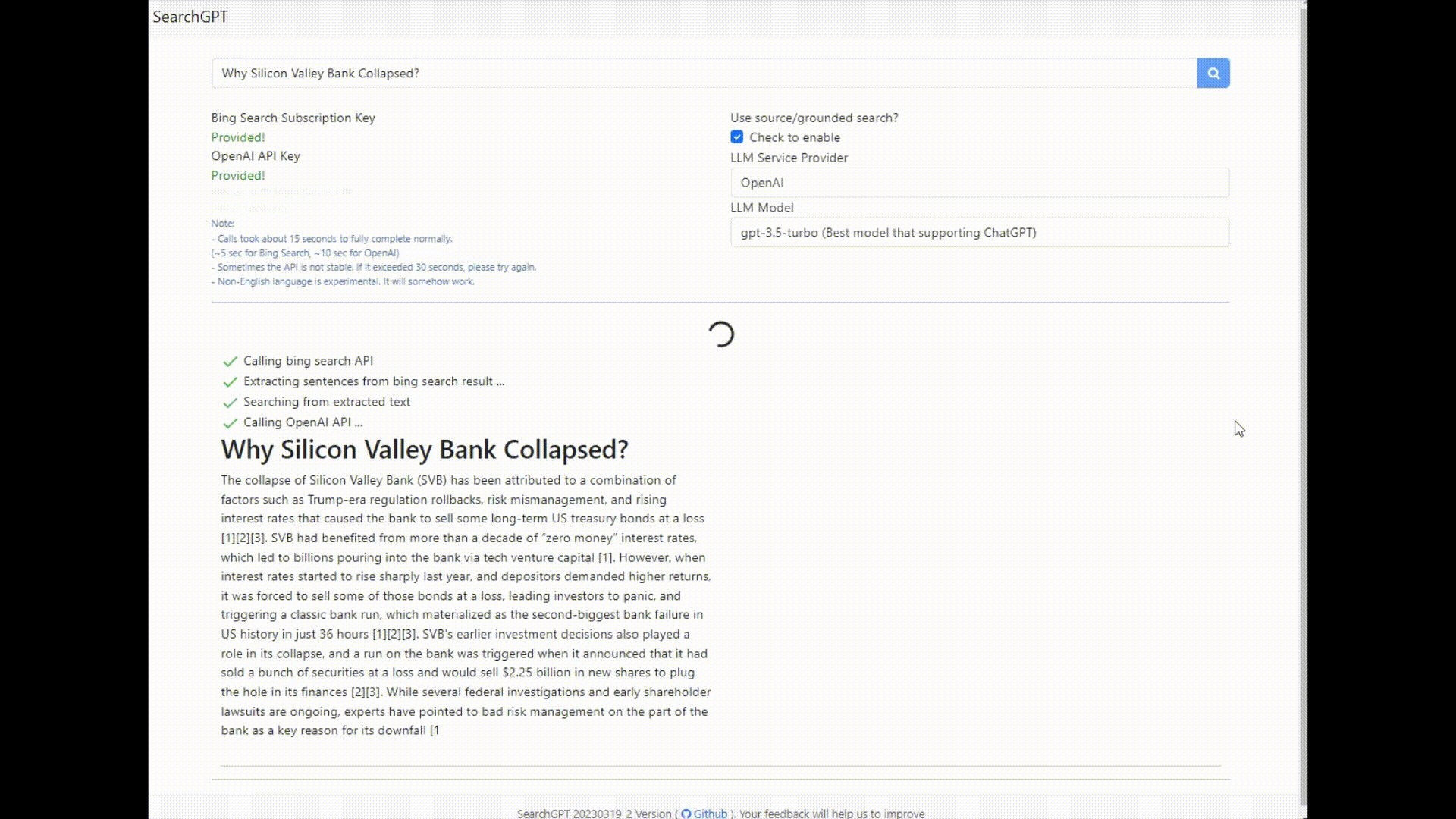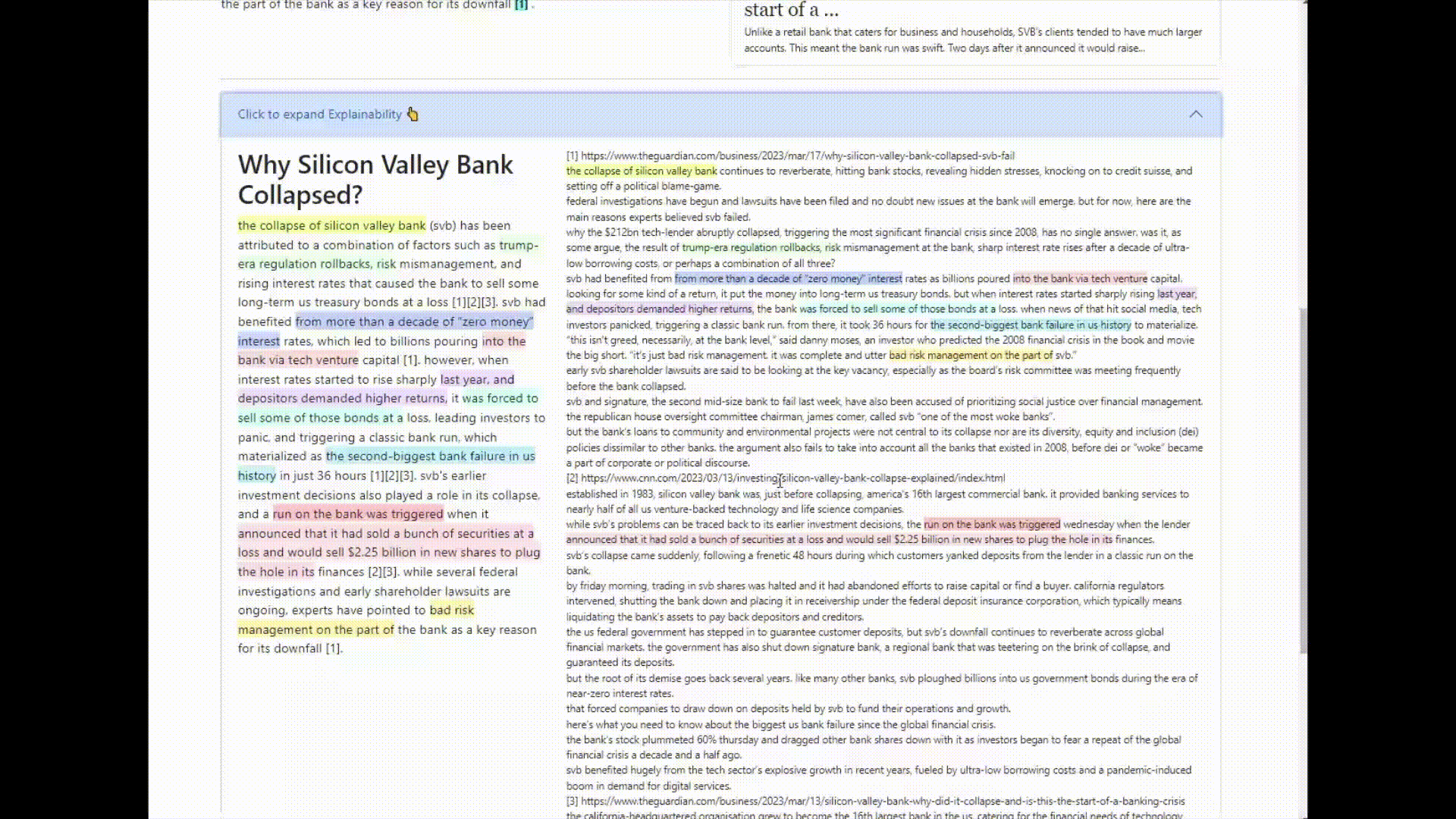
searchGPT is a search engine or question-answer bot based on LLM to give natural language answers. You may see the footnote which is the reference of sources from the web. Below there is a explainability view to show how the response is related to the sources.
Why Grounded though?
Because it is impossible for the LLM to learn everything during the training, thus real-time factual information is needed for reference.
This project tried to reproduce work like Bing and perplexity AI which have external references to support the answer of LLM.
Some examples of good grounded answer from searchGPT and wrong ungrounded answer from ChatGPT is mentioned in the github.