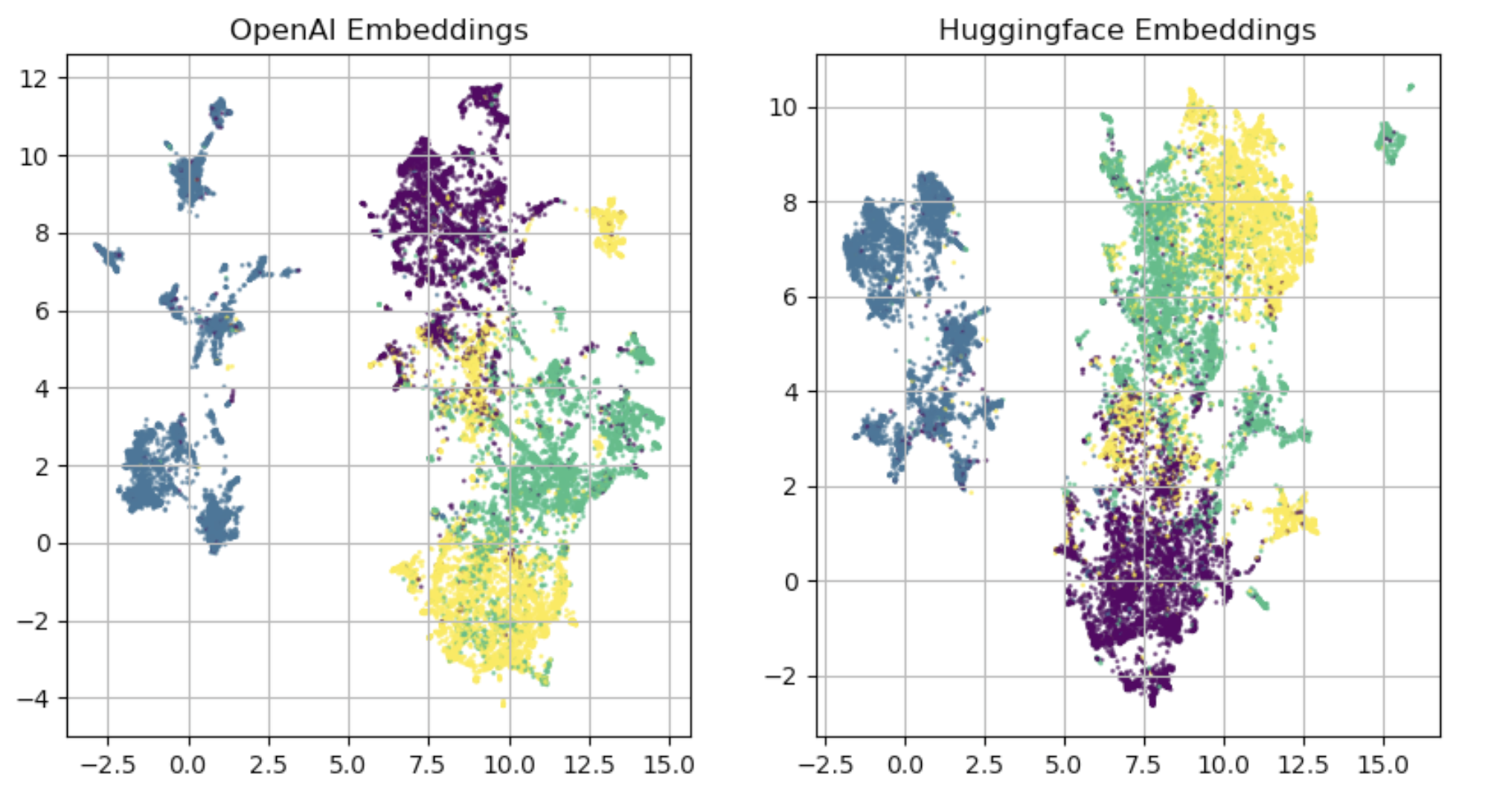
 [Discussion] Compare OpenAI and SentenceTransformer Sentence Embeddings
[Discussion] Compare OpenAI and SentenceTransformer Sentence EmbeddingsSubmitted by Simusid t3_11okrni in MachineLearning
Simusid OP t1_jbu5594 wrote
Reply to comment by pyepyepie in [Discussion] Compare OpenAI and SentenceTransformer Sentence Embeddings by Simusid
Actually the curated dataset (ref github in original post) is almost perfectly balanced. And yes, sentence embeddings is probably the SOTA approach today.
I agree that when I say the graphs "seems similar", that is a very qualitative label. However I would not say it "means nothing". At the far extreme if you plot:
x = UMAP().fit(np.random.random((10000,75)))
plt.scatter(x.embedding_[:,0], x.embedding_[:,1], s=1)
You will get "hot garbage", a big blob. My goal, and my only goal was to visually see how "blobby" OpenAI was vs ST. And clearly they are visually similar.
pyepyepie t1_jbu75ec wrote
Let's agree to disagree. Your example shows random data while I talk about how much of the information your plot actually shows after dimensionality reduction (you can't know).
Honestly, I am not sure what your work actually means since the details are kept secret - I think you can shut my mouth by reporting a little more or releasing the data, but more importantly - it would make your work a significant contribution.
Edit: I would like to see a comparison of the plot with a very simple method, e.g. mean of word embeddings. My hypothesis is that it will look similar as well.
Viewing a single comment thread. View all comments