 [Discussion] Compare OpenAI and SentenceTransformer Sentence Embeddings
[Discussion] Compare OpenAI and SentenceTransformer Sentence EmbeddingsSubmitted by Simusid t3_11okrni in MachineLearning
pyepyepie t1_jbtsc3n wrote
Your plot doesn't mean much - when you use UMAP you can't even measure the explained variance, differences can be more nuanced than what you get from the results. I would evaluate with some semantic similarity or ranking.
For the "91% vs 89%" - you need to pick the classification task very carefully if you don't describe what it was then it also literally means nothing.
That being said, thanks for the efforts.
Simusid OP t1_jbu229y wrote
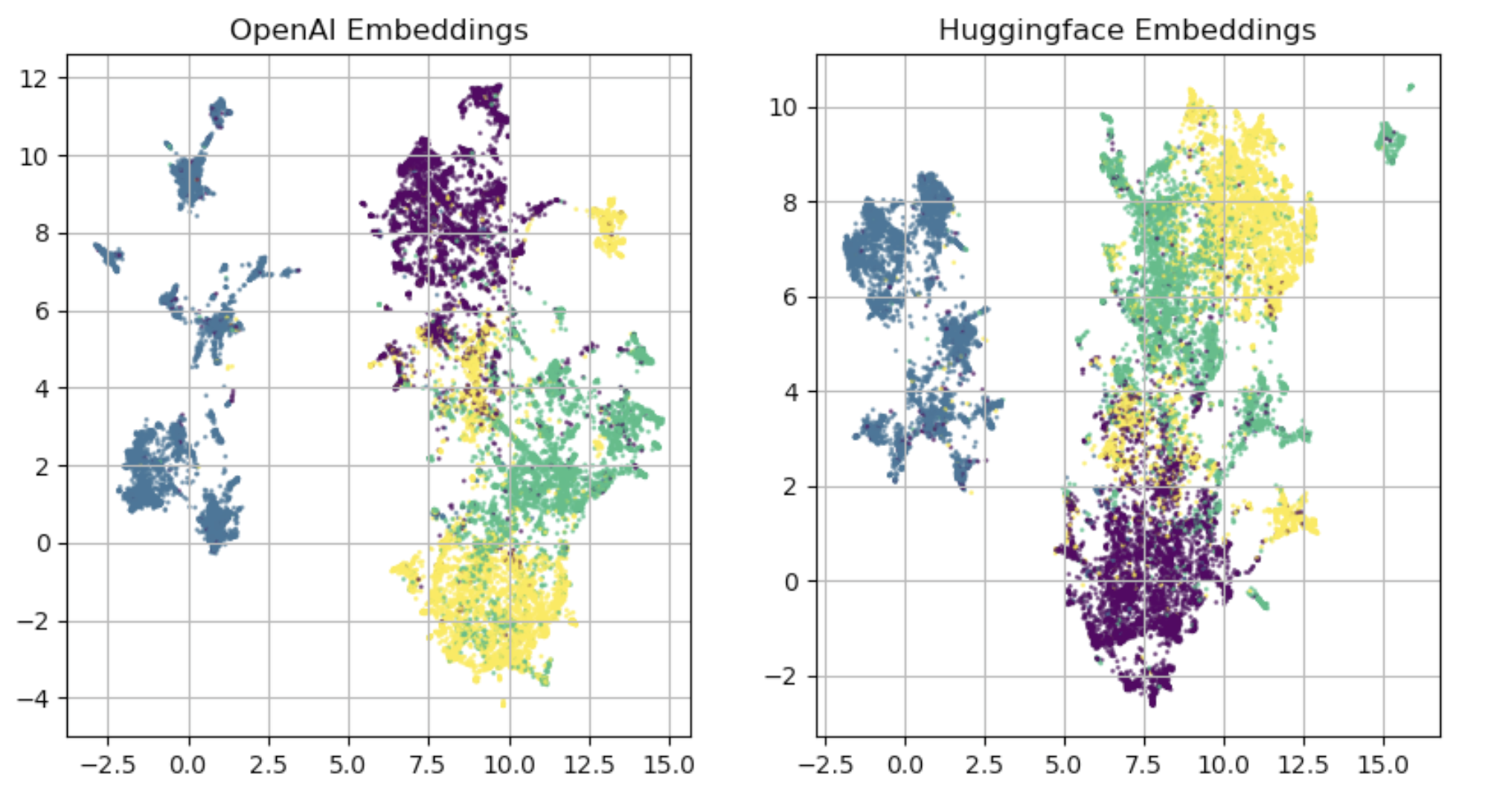
Regarding the plot, the intent was not to measure anything, nor identify any specific differences. UMAP is an important tool for humans to get a sense of what is going on at a high level. I think if you ever use a UMAP plot for analytic results, you're using it incorrectly.
At a high level I wanted to see if there were very distinct clusters or amorphous overlapping blobs and to see if one embedding was very distinct. I think these UMAPs clearly show good and similar clustering.
Regarding the classification task; Again, this is a notional task and not trying to solve a concrete problem. The goal was to use nearly identical models with both sets of embeddings to see if there were consistent differences. There were. The OpenAI models marginally outperforms the SentenceTransformer models every single time (several hundreds runs with various hyperparameters). Whether it's a "carefully chosen" task or not is immaterial. In this case "carefully chosen" means softmax classification accuracy of the 4 labels in the curated dataset.
pyepyepie t1_jbu3245 wrote
I think you misunderstood my comment. What I say is, that since you have no way to measure how well UMAP worked and how much of the variance of the data this plot contains, the fact that it "seems similar" means nothing (I am really not an expert on it, if I get it wrong feel free to correct me). Additionally, I am not sure how balanced the dataset you used for classification is, and if sentence embeddings are even the right approach for that specific task.
It might be the case - for example, that the OpenAI embeddings + the FFW network classify the data perfectly/as well as you can since the dataset is very imbalanced and the annotation is imperfect/categories are very similar. In this case, 89% vs 91% could be a huge difference. In fact, for some datasets the "majority classifier" would yield high accuracy, I would start by reporting precision & recall.
Again, I don't want to be "the negative guy" but there are serious flaws that make me unable to make any conclusion based on it (I find the project very important and interesting). Could you release the data of your experiments (vectors, dataset) so other people (I might as well) can look into it more deeply?
Simusid OP t1_jbu5594 wrote
Actually the curated dataset (ref github in original post) is almost perfectly balanced. And yes, sentence embeddings is probably the SOTA approach today.
I agree that when I say the graphs "seems similar", that is a very qualitative label. However I would not say it "means nothing". At the far extreme if you plot:
x = UMAP().fit(np.random.random((10000,75)))
plt.scatter(x.embedding_[:,0], x.embedding_[:,1], s=1)
You will get "hot garbage", a big blob. My goal, and my only goal was to visually see how "blobby" OpenAI was vs ST. And clearly they are visually similar.
pyepyepie t1_jbu75ec wrote
Let's agree to disagree. Your example shows random data while I talk about how much of the information your plot actually shows after dimensionality reduction (you can't know).
Honestly, I am not sure what your work actually means since the details are kept secret - I think you can shut my mouth by reporting a little more or releasing the data, but more importantly - it would make your work a significant contribution.
Edit: I would like to see a comparison of the plot with a very simple method, e.g. mean of word embeddings. My hypothesis is that it will look similar as well.
Viewing a single comment thread. View all comments