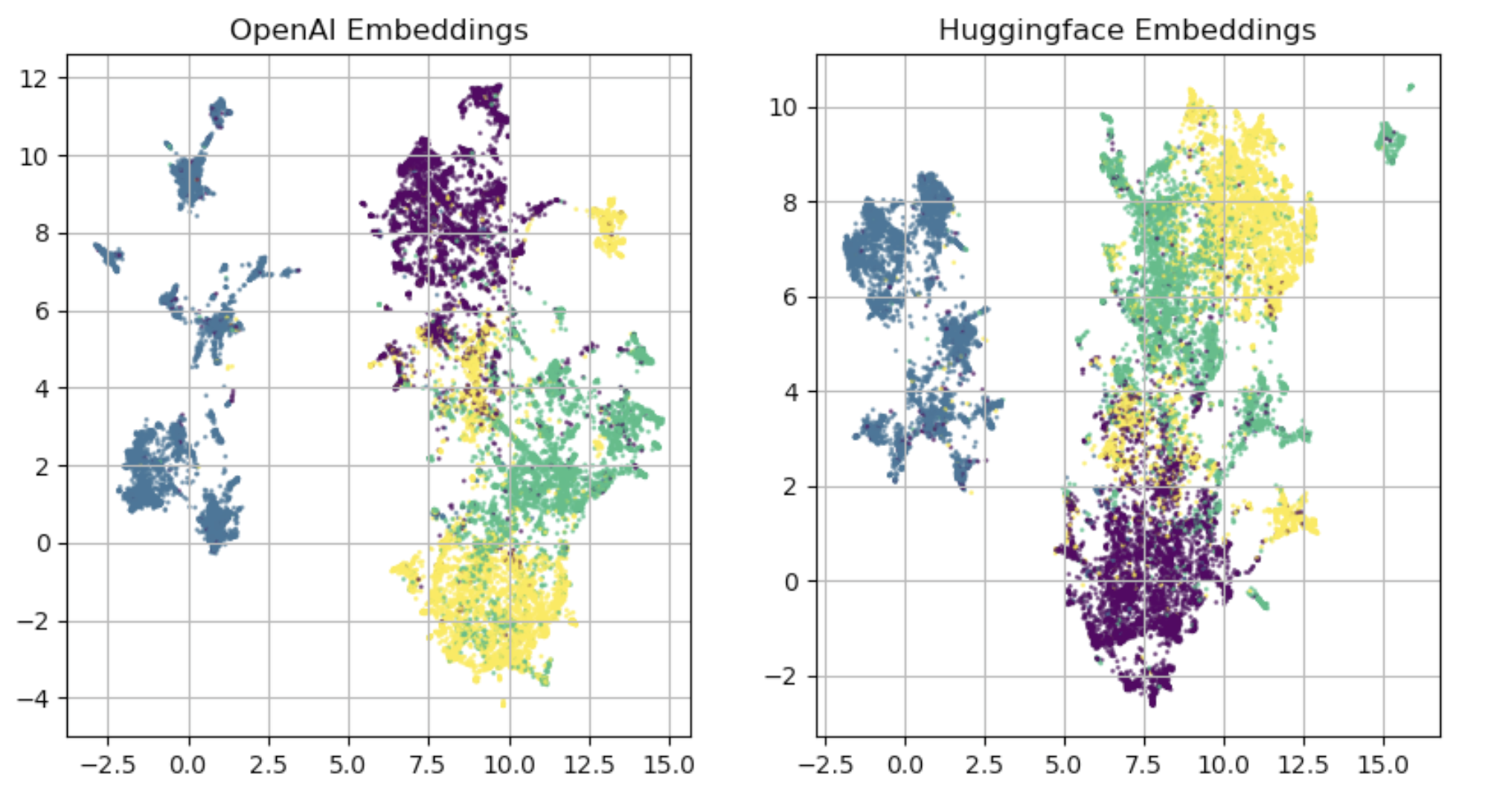
 [Discussion] Compare OpenAI and SentenceTransformer Sentence Embeddings
[Discussion] Compare OpenAI and SentenceTransformer Sentence EmbeddingsSubmitted by Simusid t3_11okrni in MachineLearning
Simusid OP t1_jbsyp5n wrote
Yesterday I set up a paid account at OpenAI. I have been using the free sentence-transformers library and models for many months with good results. I compared the performance of the two by encoding 20K vectors from this repo https://github.com/mhjabreel/CharCnn_Keras. I did no preprocessing or cleanup of the input text. The OpenAI model is text-embedding-ada-002 and the SentenceTransformer model is all-mpnet-base-v2. The plots are simple UMAP(), with all defaults.I also built a very generic model with 3 dense layers, nothing fancy. I ran each model ten times for the two embeddings, fitting with EarlyStopping, and evaluating with hold out data. The average results were HF 89% and OpenAI 91.1%. This is not rigorous or conclusive, but for my purposes I'm happy sticking with SentenceTransformers. If I need to chase decimal points of performance, I will use OpenAi.
Edit - The second graph should be titled "SentenceTransformer" not HuggingFace.
ID4gotten t1_jbt63ni wrote
Maybe I'm being "dense", but what task was your network trained to accomplish? That wasn't clear to me from your description.
Simusid OP t1_jbt91tb wrote
My main goal was to just visualize the embeddings to see if they are grossly different. They are not. That is just a qualitative view. My second goal was to use the embeddings with a trivial supervised classifier. The dataset is labeled with four labels. So I made a generic network to see if there was any consistency in the training. And regardless of hyperparameters, the OpenAI embeddings seemed to always outperform the SentenceTransformer embeddings, slightly but consistency.
This was not meant to be rigorous. I did this to get a general feel of the quality of the embeddings, plus to get a little experience with the OpenAI API.
quitenominal t1_jbtr6g7 wrote
fwiw this has also been my finding when comparing these two embeddings for classification tasks. Better, but not enough to justify the cost
polandtown t1_jbu2zqe wrote
Learning here, but how are you axes defined? Some kind of factor(s) or component(s) extracted from each individual embedding? Thanks for the visualization, as it made me curious and interested! Good work!
Simusid OP t1_jbu3q8m wrote
Here is some explanation about UMAP axes and why they should usually be ignored: https://stats.stackexchange.com/questions/527235/how-to-interpret-axis-of-umap
Basically it's because they are nonlinear.
onkus t1_jbwftny wrote
Doesn’t this also make it essentially impossible to compare the two figures you’ve shown?
Thog78 t1_jbyh4w1 wrote
What you're looking for when comparing UMAPs is if the local relationships are the same. Try to recognize clusters and see their neighbors, or whether they are distinct or not. A much finer colored clustering based on another reduction (typically PCA) helps with that. Without clustering, you can only try to recognize landmarks from their size and shape.
[deleted] t1_jbyaq18 wrote
[deleted]
polandtown t1_jbu56lb wrote
Thanks!
[deleted] t1_jbtcsig wrote
[deleted]
Geneocrat t1_jbu4law wrote
Thanks for asking the questions seemingly obvious questions so that I don’t have to wonder.
imaginethezmell t1_jbszsey wrote
openai is 8k
how about sentence transformer
montcarl t1_jbtexjk wrote
This is an important point. The performance similarities indicate that the sentence lengths of the 20k dataset were mostly within the SentenceTransformer max length cutoff. It would be nice to confirm this and also run another test with longer examples. This new test should result in a larger performance gap.
Simusid OP t1_jbt13iy wrote
8K? I'm not sure what you're referring to.
VarietyElderberry t1_jbt5zkd wrote
I'm assuming u/imaginethezmell is referring to the context length. Indeed, if there is a need for longer context lengths, then OpenAI outcompetes SentenceTransformer which has a default context length of 128.
LetterRip t1_jbtn573 wrote
number of total tokens in input + output.
rajanjedi t1_jbt625q wrote
Number of tokens in the input perhaps?
[deleted] t1_jbt7rkv wrote
[deleted]
Viewing a single comment thread. View all comments